
11、线程池
池化技术
程序的运行,其本质上,是对系统资源(CPU、内存、磁盘、网络等等)的使用。如何高效的使用这些资源 是我们编程优化演进的一个方向。今天说的线程池就是一种对CPU利用的优化手段。
通过学习线程池原理,明白所有池化技术的基本设计思路。遇到其他相似问题可以解决。
前面提到一个名词——池化技术,那么到底什么是池化技术呢 ?
池化技术简单点来说,就是提前保存大量的资源,以备不时之需。在机器资源有限的情况下,使用池化 技术可以大大的提高资源的利用率,提升性能等。
在编程领域,比较典型的池化技术有:线程池、连接池、内存池、对象池等。
我们通过创建一个线程对象,并且实现Runnable接口就可以实现一个简单的线程。可以利用上多核 CPU。当一个任务结束,当前线程就接收。
但很多时候,我们不止会执行一个任务。如果每次都是如此的创建线程->执行任务->销毁线程,会造成很大的性能开销。
那能否一个线程创建后,执行完一个任务后,又去执行另一个任务,而不是销毁。这就是线程池。
这也就是池化技术的思想,通过预先创建好多个线程,放在池中,这样可以在需要使用线程的时候直接获取,避免多次重复创建、销毁带来的开销。
为什么使用线程池
10 年前单核CPU电脑,假的多线程,像马戏团小丑玩多个球 ,CPU 需要来回切换。
现在是多核电脑,多个线程各自跑在独立的CPU上,不用切换效率高。
线程池的优势:
线程池做的工作主要是:控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这 些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
它的主要特点为:线程复用,控制最大并发数,管理线程。
第一:降低资源消耗,通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等待线程创建就能立即执行。
第三:提高线程的可管理性,线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配,调优和监控。
ExecutorService
线程池的三大方法
Java中的线程池是通过 Executor 框架实现的,该框架中用到了 Executor ,Executors, ExecutorService,ThreadPoolExecutor 这几个类。
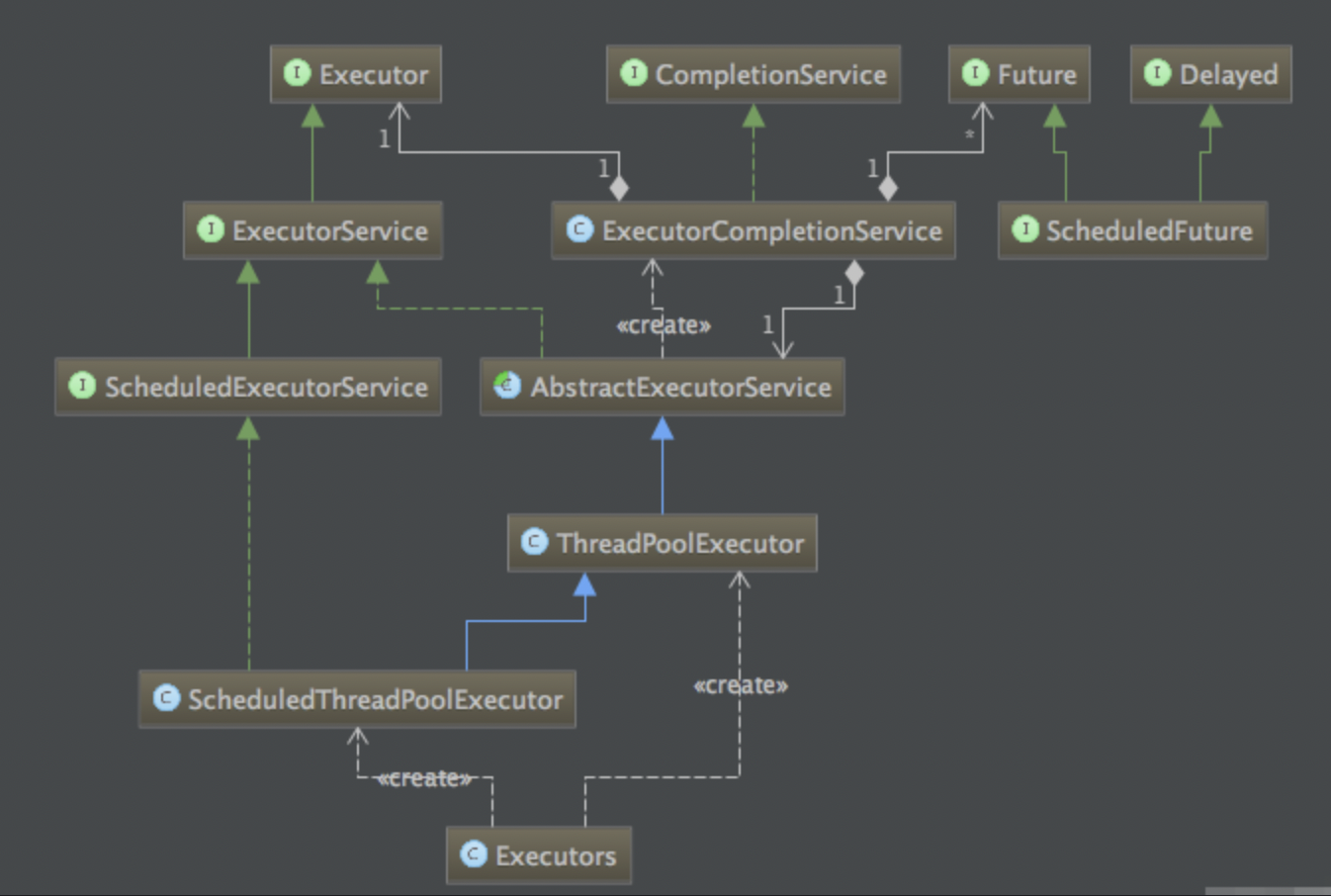
三大方法说明:
-
Executors.newFixedThreadPool(int)执行长期任务性能好,创建一个线程池,一池有N个固定的线程,有固定线程数的线程。
-
Executors.newSingleThreadExecutor()只有一个线程
-
Executors.newCachedThreadPool()执行很多短期异步任务,线程池根据需要创建新线程,但在先构建的线程可用时将重用他们。 可扩容,遇强则强
public class MyThreadPoolDemo {
public static void main(String[] args) {
/** 1、池子大小 5
* 模拟有10个顾客过来银行办理业务,池子中只有5个工作人员受理业务
*/
// ExecutorService threadPool = Executors.newFixedThreadPool(5);
/** 2、有且只有一个固定的线程
* 模拟有10个顾客过来银行办理业务,池子中只有1个工作人员受理业务
*/
// ExecutorService threadPool = Executors.newSingleThreadExecutor();
/** 3、一池N线程,可扩容伸缩
* 模拟有10个顾客过来银行办理业务,池子中N个工作人员受理业务
*/
ExecutorService threadPool = Executors.newCachedThreadPool();
try {
for (int i = 1; i <= 10; i++) {
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + " 办理业务");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown(); // 用完记得关闭
}
}
}
ThreadPoolExecutor
ThreadPoolExecutor 七大参数
查看三大方法的调用源码,发现本质都是调用了 new ThreadPoolExecutor ( 7 大参数 )
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
}
1、corePollSize
核心线程数。在创建了线程池后,线程中没有任何线程,等到有任务到来时才创建线程去执行任务。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到 corePoolSize 后,就会把到达的任务放到缓存队列当中。
2、maximumPoolSize
最大线程数。表明线程中最多能够创建的线程数量,此值必须大于等于1。
3、keepAliveTime
空闲的线程保留的时间,达到这个时间后,自动释放
4、TimeUnit
空闲线程的保留时间单位。
TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒
5、BlockingQueue<Runnable> workQueue
阻塞队列,存储等待执行的任务。参数有ArrayBlockingQueue、 LinkedBlockingQueue、SynchronousQueue可选。
6、ThreadFactory
线程工厂,用来创建线程,一般默认即可
7、RejectedExecutionHandler
队列已满,而且任务量大于最大线程的异常处理策略。有以下取值
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
ThreadPoolExecutor层工作原理
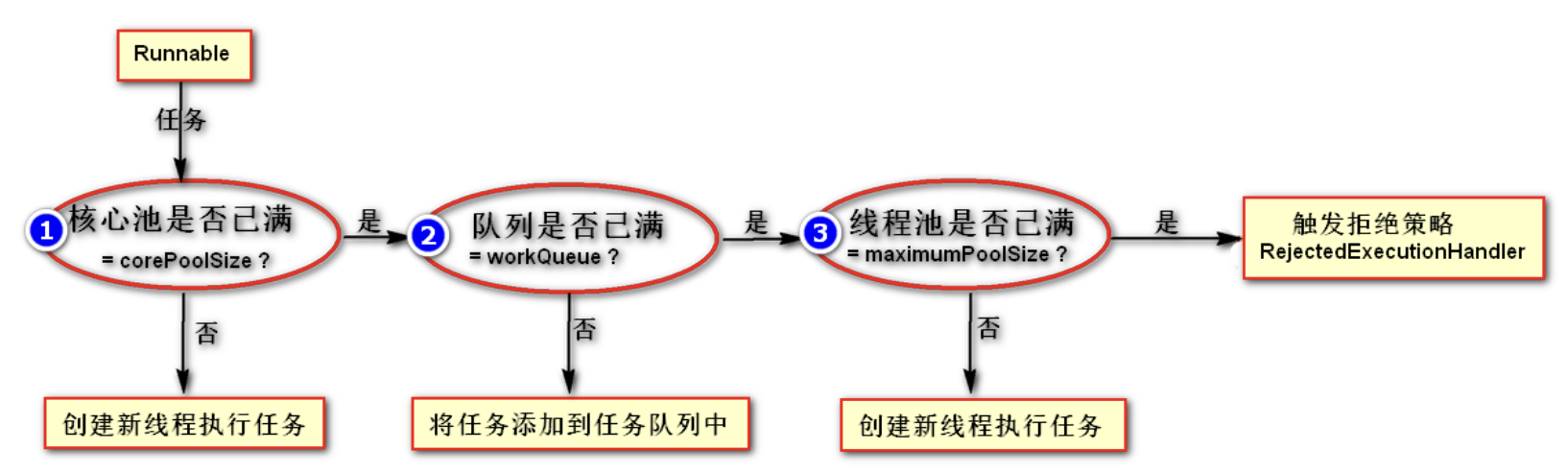
举例:8个人进银行办理业务
1、1~2人被受理(核心大小core)
2、3~5人进入队列(Queue)
3、6~8人到最大线程池(扩容大小max)
4、再有人进来就要被拒绝策略接受了
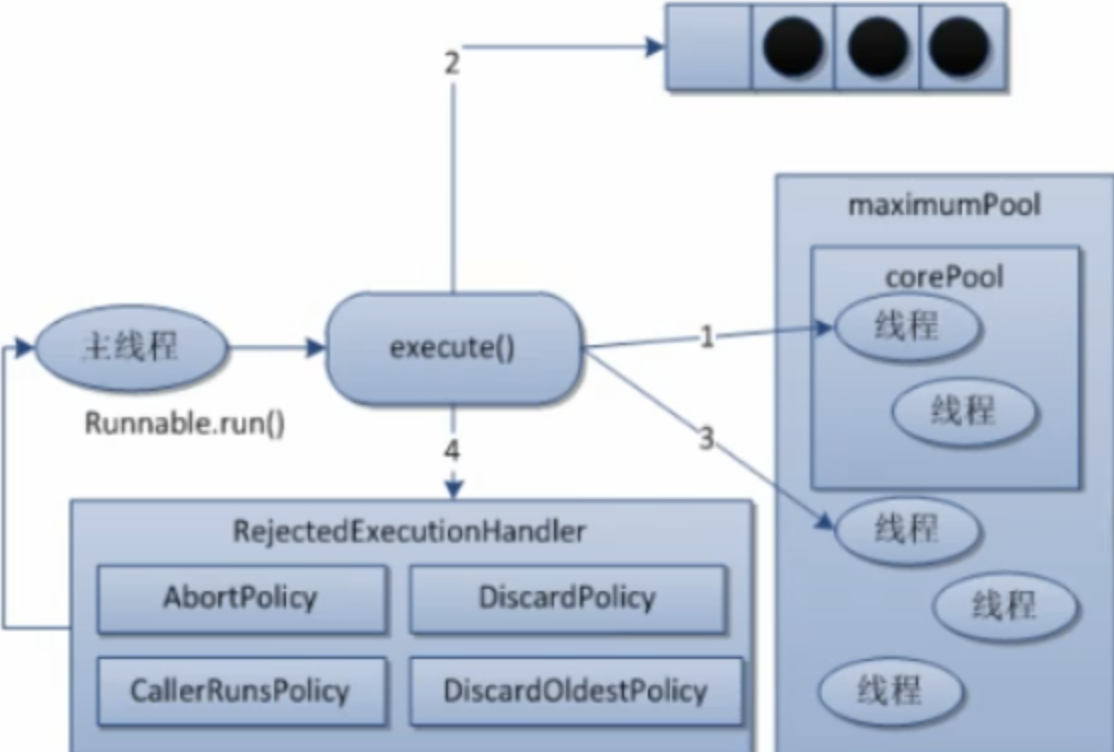
1、在创建了线程池后,开始等待请求。
2、当调用execute()方法添加一个请求任务时,线程池会做出如下判断:
- 如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务
- 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列
- 如果这个时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非 核心线程立刻运行这个任务
- 如果队列满了且正在运行的线程数量大于或等于1Size,那么线程池会启动饱和拒绝策略来执行。
3、当一个线程完成任务时,它会从队列中取下一个任务来执行
4、 当一个线程无事可做超过一定的时间(keepAliveTime)时,线程会判断:
如果当前运行的线程数大于corePollSize,那么这个线程就被停掉。
所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
tip 线程池用哪个?生产中如何设置合理参数
Executors 中 JDK 已经给你提供了,为什么不用?

代码测试:
线程池的拒绝策略:
RejectedExecutionHandler rejected = null;
//默认,队列满了丢任务,抛出异常
rejected = new ThreadPoolExecutor.AbortPolicy();
//队列满了丢任务,不抛出异常【如果允许任务丢失这是最好的】
rejected = new ThreadPoolExecutor.DiscardPolicy();
//将最早进入队列的任务删,之后再尝试加入队列
rejected = new ThreadPoolExecutor.DiscardOldestPolicy();
////如果添加到线程池失败,那么主线程会自己去执行该任务,回退
rejected = new ThreadPoolExecutor.CallerRunsPolicy();
public class MyThreadPoolDemo2 {
public static void main(String[] args) {
// 自定义 ThreadPoolExecutor
ExecutorService threadPool = new ThreadPoolExecutor(
2,
Runtime.getRuntime().availableProcessors(),
2L,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardPolicy());
try {
// 模拟有6,7,8,9,10个顾客过来银行办理业务,观察结果情况
// 最大容量为:maximumPoolSize + workQueue = 最大容量数
for (int i = 1; i <= 19; i++) {
int num = i;
threadPool.execute(() -> {
System.out.println(num + " " + Thread.currentThread().getName() + " ok");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown(); // 用完记得关闭
}
}
}
线程是否越多越好?
一个计算为主的程序(专业一点称为CPU密集型程序)。多线程跑的时候,可以充分利用起所有的 cpu 核心,比如说4个核心的cpu,开4个线程的时候,可以同时跑4个线程的运算任务,此时是最大效率。但是如果线程远远超出cpu核心数量反而会使得任务效率下降,因为频繁的切换线程也是要消耗时间的。因此对于cpu密集型的任务来说,线程数等于cpu数是最好的了。
如果是一个磁盘或网络为主的程序(IO密集型)。一个线程处在IO等待的时候,另一个线程还可以在 CPU里面跑,有时候CPU闲着没事干,所有的线程都在等着IO,这时候他们就是同时的了,而单线程的话此时还是在一个一个等待的。我们都知道IO的速度比起CPU来是慢到令人发指的。所以开多线程,比 方说多线程网络传输,多线程往不同的目录写文件,等等。此时线程数等于IO任务数是最佳的。
12、四大函数式接口
在java.util.function包下,Java 内置核心四大函数式接口,可以使用lambda表达式
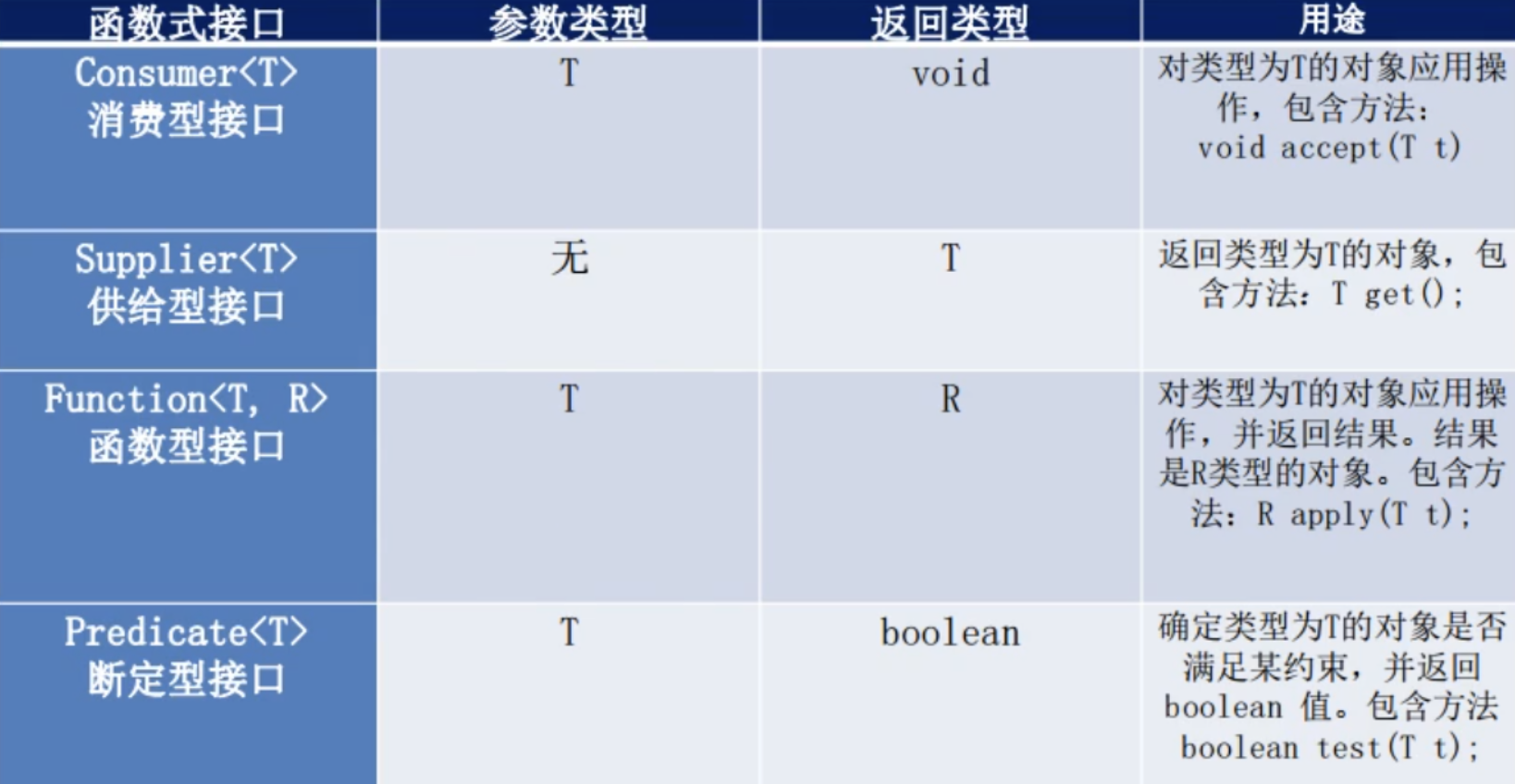
Function
函数型接口,有一个输入,有一个输出
package com.oddfar.function;
import java.util.function.Function;
/**
* @author zhiyuan
*/
public class Demo01 {
public static void main(String[] args) {
// Function<String,Integer> function = new Function<String,Integer>() {
// @Override
// public Integer apply(String s) {
// return s.length();
// }
// };
Function<String,Integer> function = (s)->{return s.length();};
System.out.println(function.apply("abc"));
}
}
Predicate
断定型接口,有一个输入参数,返回只有布尔值。
public class Demo02 {
public static void main(String[] args) {
// Predicate<String> predicate = new Predicate<String>() {
// @Override
// public boolean test(String s) {
// return s.isEmpty();
// }
// };
Predicate<String> predicate = (s)->{return s.isEmpty();};
System.out.println(predicate.test("abc"));
}
}
Consumer
消费型接口,有一个输入参数,没有返回值
public class Demo03 {
public static void main(String[] args) {
// Consumer<String> consumer = new Consumer<String>() {
// @Override
// public void accept(String s) {
// System.out.println(s);
// }
// };
Consumer<String> consumer = s -> { System.out.println(s); };
consumer.accept("abc");
}
}
Supplier
供给型接口,没有输入参数,只有返回参数
public class Demo04 {
public static void main(String[] args) {
// Supplier<String> supplier = new Supplier<String>() {
// @Override
// public String get() {
// return null;
// }
// };
Supplier<String> supplier = () -> { return "abc";};
System.out.println(supplier.get());
}
}
13、Stream流式计算
流(Stream)到底是什么呢?
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
“集合讲的是数据,流讲的是计算!”
特点:
-
Stream 自己不会存储元素
-
Stream 不会改变源对象,相反,他们会返回一个持有结果的新Stream。
-
Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
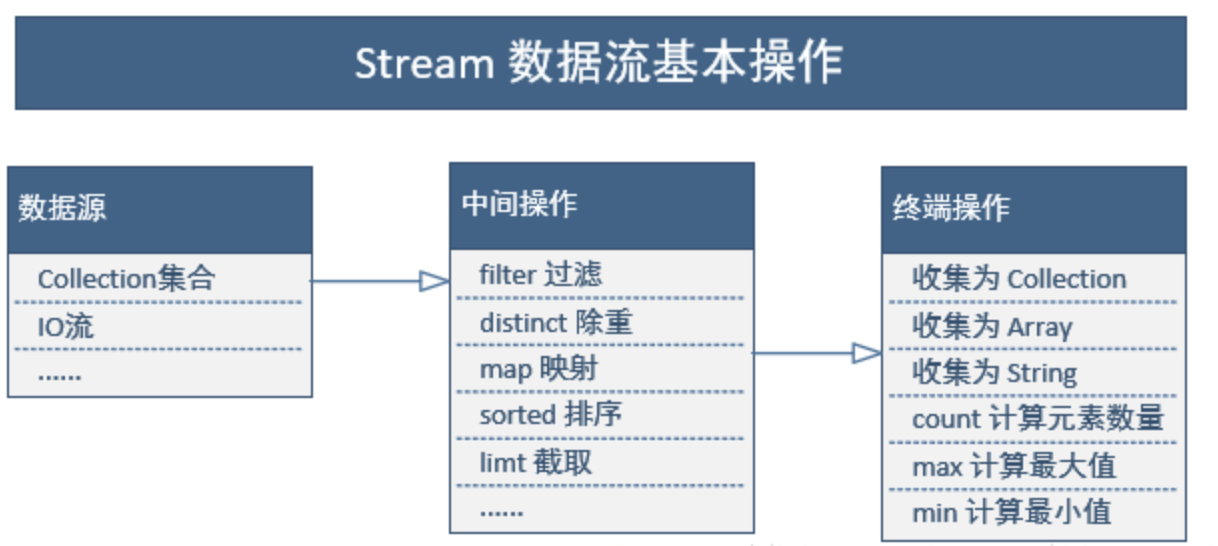
代码举例
User实体类
public class User {
private int id;
private String userName;
private int age;
//get、set、有参/无参构造器、toString
}
Stream算法题
package com.oddfar.stream;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
/**
* 题目:请按照给出数据,找出同时满足以下条件的用户
* 也即以下条件:
* 1、全部满足偶数ID
* 2、年龄大于24
* 3、用户名转为大写
* 4、用户名字母倒排序
* 5、只输出一个用户名字 limit
*/
public class StreamDemo {
public static void main(String[] args) {
User u1 = new User(11, "a", 23);
User u2 = new User(12, "b", 24);
User u3 = new User(13, "c", 22);
User u4 = new User(14, "d", 28);
User u5 = new User(16, "e", 26);
List<User> list = Arrays.asList(u1, u2, u3, u4, u5);
/**
* 1. 首先我们需要将 list 转化为stream流
* 2. 然后将用户过滤出来,这里用到一个函数式接口 Predicate<? super T>,我们可以使用lambda表达式简化
* 3. 这里面传递的参数,就是Stream流的泛型类型,也就是User,所以,这里可以直接返回用户id为偶数的用户信息;
* 4. 通过forEach进行遍历,直接简化输出 System.out::println
*/
list.stream()
.filter(u -> {
return u.getId() % 2 == 0;
})
.filter(u -> {
return u.getAge() > 24;
})
.map(u -> {
return u.getUserName().toUpperCase();
})
//.sorted() //默认正排序 自己用 compareTo 比较
.sorted((o1, o2) -> {
return o2.compareTo(o1);
})
.limit(1)
.forEach(System.out::println);
// map解释:
List<Integer> list2 = Arrays.asList(1, 2, 3);
list2 = list2.stream().map(x -> {
return x * 2;
}).collect(Collectors.toList());
for (Integer element : list2) {
System.out.println(element);
}
}
}
14、分支合并
什么是ForkJoin
从JDK1.7开始,Java提供 Fork/Join 框架用于并行执行任务,它的思想就是讲一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。
这种思想和MapReduce很像(input --> split --> map --> reduce --> output)
主要有两步:
- 第一、任务切分
- 第二、结果合并
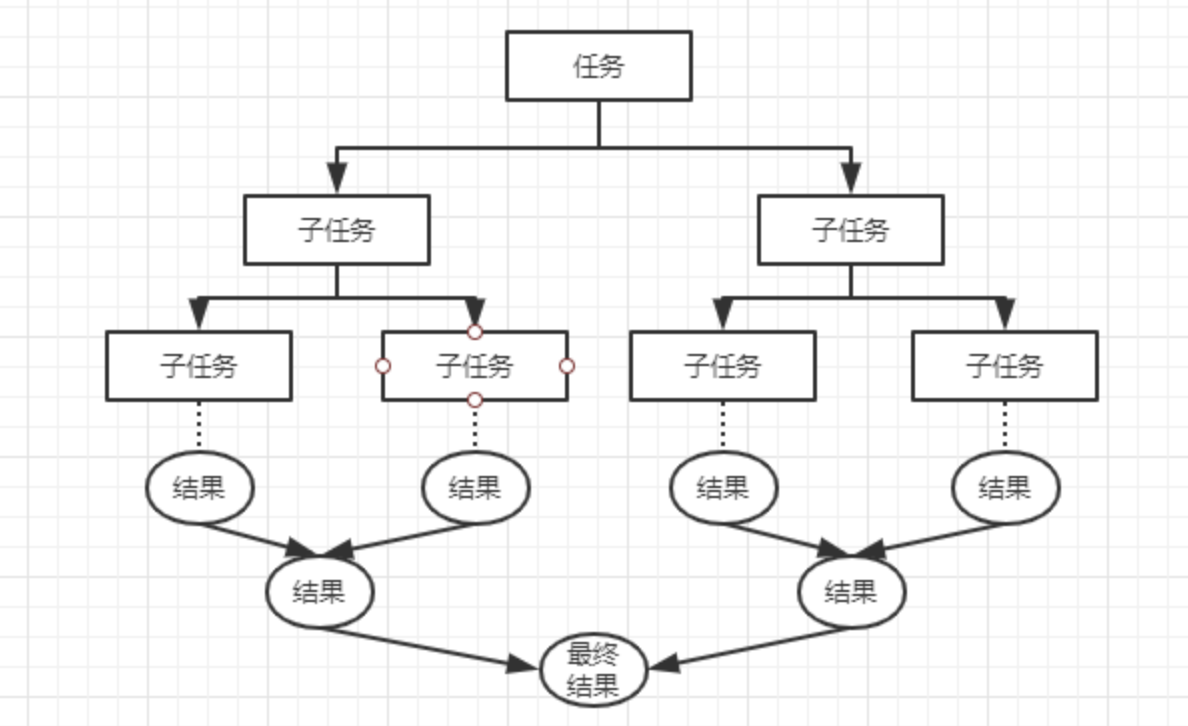
它的模型大致是这样的:线程池中的每个线程都有自己的工作队列
(PS:这一点和ThreadPoolExecutor 不同,ThreadPoolExecutor是所有线程公用一个工作队列,所有线程都从这个工作队列中取任务)
当 自己队列中的任务都完成以后,会从其它线程的工作队列中偷一个任务执行,这样可以充分利用资源。
工作窃取
另外,forkjoin有一个工作窃取的概念。简单理解,就是一个工作线程下会维护一个包含多个子任务的双端队列。而对于每个工作线程来说,会从头部到尾部依次执行任务。这时,总会有一些线程执行的速度较快,很快就把所有任务消耗完了。那这个时候怎么办呢,总不能空等着吧,多浪费资源啊。
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
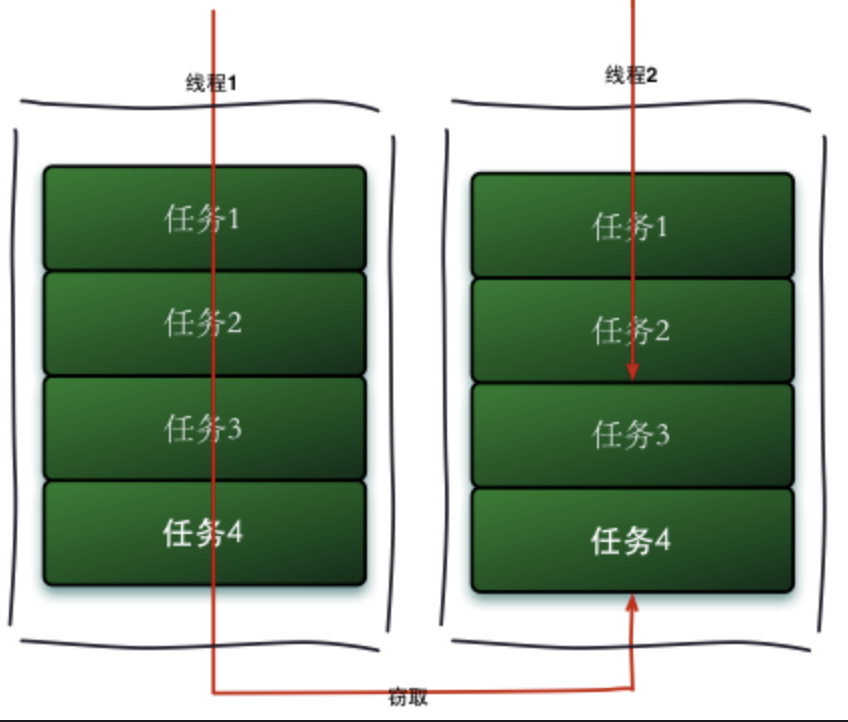
那么为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
于是,先做完任务的工作线程会从其他未完成任务的线程尾部依次获取任务去执行。这样就可以充分利用CPU的资源。这个非常好理解,就比如有个妹子程序员做任务比较慢,那么其他猿就可以帮她分担一 些任务,这简直是双赢的局面啊,妹子开心了,你也开心了。
核心类
1、ForkJoinPool
WorkQueue是一个ForkJoinPool中的内部类,它是线程池中线程的工作队列的一个封装,支持任务窃取。
什么叫线程的任务窃取呢?就是说你和你的一个伙伴一起吃水果,你的那份吃完了,他那份没吃完,那你就偷偷的拿了他的一些水果吃了。存在执行2个任务的子线程,这里要讲成存在A,B两个了。
WorkQueue在执行任务,A的任务执行完了,B的任务没执行完,那么A的WorkQueue就从B的 WorkQueue的ForkJoinTask数组中拿走了一部分尾部的任务来执行,可以合理的提高运行和计算效率。
每个线程都有一个WorkQueue,而WorkQueue中有执行任务的线程(ForkJoinWorkerThread owner),还有这个线程需要处理的任务(ForkJoinTask<?>[] array)。那么这个新提交的任务就是加到array中。
2、ForkJoinTask
ForkJoinTask代表运行在ForkJoinPool中的任务。
主要方法:
- fork() 在当前线程运行的线程池中安排一个异步执行。简单的理解就是再创建一个子任务
- join() 当任务完成的时候返回计算结果。
- invoke() 开始执行任务,如果必要,等待计算完成。
子类: Recursive :递归
- RecursiveAction 一个递归无结果的ForkJoinTask(没有返回值)
- RecursiveTask 一个递归有结果的ForkJoinTask(有返回值)
代码测试
核心代码:
package com.oddfar.forkJoin;
import java.util.concurrent.RecursiveTask;
/**
* @author zhiyuan
*/
public class ForkJoinWork extends RecursiveTask<Long> {
private Long start;//起始值
private Long end;//结束值
public static final Long critical = 10000L;//临界值
public ForkJoinWork(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
//判断是否是拆分完毕
Long lenth = end - start;
if (lenth <= critical) {
//如果拆分完毕就相加
Long sum = 0L;
for (Long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
//没有拆分完毕就开始拆分
Long middle = (end + start) / 2;//计算的两个值的中间值
ForkJoinWork right = new ForkJoinWork(start, middle);
right.fork();//拆分,并压入线程队列
ForkJoinWork left = new ForkJoinWork(middle + 1, end);
left.fork();//拆分,并压入线程队列
//合并
return right.join() + left.join();
}
}
}
三种测试:
package com.oddfar.forkJoin;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.stream.LongStream;
/**
* @author zhiyuan
*/
public class ForkJoinWorkDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
test1();// 15016
test2();// 14694
test3();// 216
}
// forkjoin这个框架针对的是大任务执行,效率才会明显的看出来有提升,于是我把总数调大到20亿。
public static void test1() throws ExecutionException, InterruptedException {
//ForkJoin实现
long l = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();//实现ForkJoin 就必须有ForkJoinPool的支持
ForkJoinTask<Long> task = new ForkJoinWork(0L, 2000000000L);//参数为起始值与结束值
ForkJoinTask<Long> result = forkJoinPool.submit(task);
Long aLong = result.get();
long l1 = System.currentTimeMillis();
System.out.println("invoke = " + aLong + " time: " + (l1 - l));
}
public static void test2() {
//普通线程实现
Long x = 0L;
Long y = 20_0000_0000L;
long start_time = System.currentTimeMillis();
for (Long i = 0L; i <= y; i++) {
x += i;
}
long end_time = System.currentTimeMillis();
System.out.println("invoke = " + x + " time: " + (end_time - start_time));
}
public static void test3() {
//Java 8 并行流的实现
long l = System.currentTimeMillis();
long reduce = LongStream.rangeClosed(0, 2000000000L).parallel().reduce(0, Long::sum);
long l1 = System.currentTimeMillis();
System.out.println("invoke = " + reduce + " time: " + (l1 - l));
}
}
打个比方,假设一个酒店有400个房间,一共有4名清洁工,每个工人每天可以打扫100个房间,这样,4 个工人满负荷工作时,400个房间全部打扫完正好需要1天。
Fork/Join的工作模式就像这样:首先,工人甲被分配了400个房间的任务,他一看任务太多了自己一个 人不行,所以先把400个房间拆成两个200,然后叫来乙,把其中一个200分给乙。紧接着,甲和乙再发现200也是个大任务,于是甲继续把200分成两个100,并把其中一个100分给丙, 类似的,乙会把其中一个100分给丁,这样,最终4个人每人分到100个房间,并发执行正好是1天。
15、异步回调
概述
Future设计的初衷:对将来某个时刻会发生的结果进行建模。
当我们需要调用一个函数方法时。如果这个函数执行很慢,那么我们就要进行等待。但有时候,我们可能并不急着要结果。因此,我们可以让被调用者立即返回,让他在后台慢慢处理这个请求。对于调用者来说,则可以先处理一些其他任务,在真正需要数据的场合再去尝试获取需要的数据。
它建模了一种异步计算,返回一个执行运算结果的引用,当运算结束后,这个引用被返回给调用方。在 Future 中出发那些潜在耗时的操作把调用线程解放出来,让它能继续执行其他有价值的工作,不再需要等待耗时的操作完成。
**Future的优点:**比更底层的Thread更易用。要使用Future,通常只需要将耗时的操作封装在一个 Callable对象中,再将它提交给ExecutorService。
为了让程序更加高效,让CPU最大效率的工作,我们会采用异步编程。首先想到的是开启一个新的线程去做某项工作。再进一步,为了让新线程可以返回一个值,告诉主线程事情做完了,于是乎 Future 粉墨登场。然而Future提供的方式是主线程主动问询新线程,要是有个回调函数就爽了。所以,为了满足 Future的某些遗憾,强大的CompletableFuture 随着Java8一起来了。
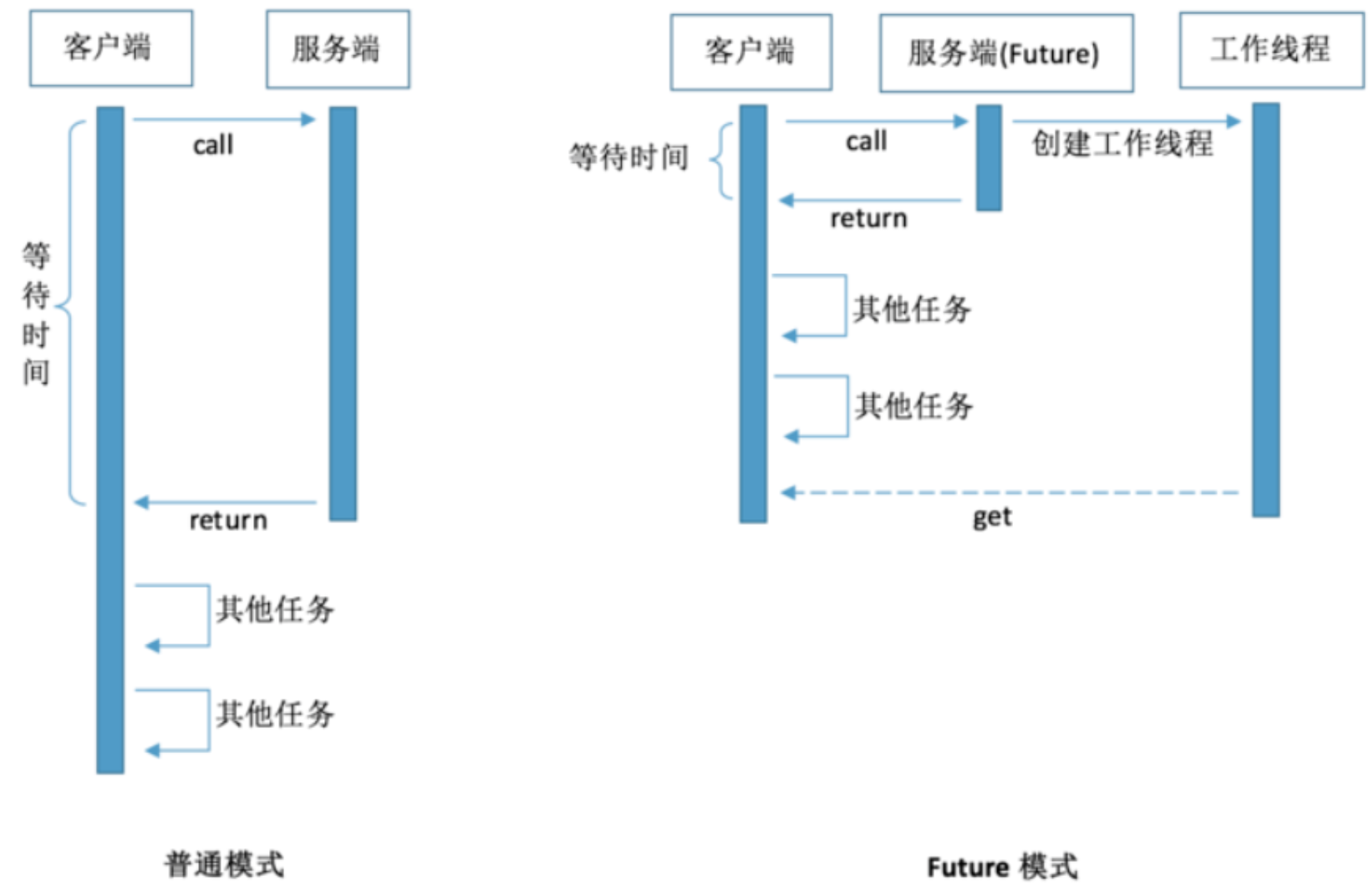
实例
没有返回值的 runAsync 异步调用
package com.oddfar.future;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;
/**
* @author zhiyuan
*/
public class Demo01 {
public static void main(String[] args) throws Exception {
//没有返回值的 runAsync 异步调用
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(
() -> {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
int i = 1;
System.out.println(Thread.currentThread().getName() + " 没有返回");
}
);
System.out.println("111111");
completableFuture.get();
System.out.println("222222");
}
}
有返回值的 供给型参数接口
public class Demo02 {
public static void main(String[] args) throws Exception {
CompletableFuture<Integer> completableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName() + " 有返回值");
// int i = 10 / 0;
return 1024;
}
);
Integer res = completableFuture.whenComplete((t, u) -> {
//编译 完成,正常结束输出
System.out.println("===t:" + t); //正常结果
System.out.println("===u:" + u); //报错的信息
}).exceptionally(e -> { //结果异常,非正常结束
System.out.println("=======exception:" + e.getMessage());
return 555;
}).get();
System.out.println(res);
}
}
16、JMM
- 请你谈谈你对 volatile 的理解
volitile 是 Java 虚拟机提供的轻量级的同步机制,三大特性:
1、保证可见性
2、不保证原子性
3、禁止指令重排
什么是JMM
JMM 本身是一种抽象的概念,并不真实存在,它描述的是一组规则或者规范~
JMM 关于同步的规定:
1、线程解锁前,必须把共享变量的值刷新回主内存
2、线程加锁前,必须读取主内存的最新值到自己的工作内存
3、加锁解锁是同一把锁
JMM即为 JAVA 内存模型(java memory model)。因为在不同的硬件生产商和不同的操作系统下,内存的访问逻辑有一定的差异,结果就是当你的代码在某个系统环境下运行良好,并且线程安全,但是换了个系统就出现各种问题。Java内存模型,就是为了屏蔽系统和硬件的差异,让一套代码在不同平台下能到达相同的访问结果。JMM从java 5开始的JSR-133发布后,已经成熟和完善起来。
JMM规定了内存主要划分为主内存和工作内存两种。此处的主内存和工作内存跟JVM内存划分(堆、 栈、方法区)是在不同的层次上进行的,如果非要对应起来,主内存对应的是Java堆中的对象实例部分,工作内存对应的是栈中的部分区域,从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
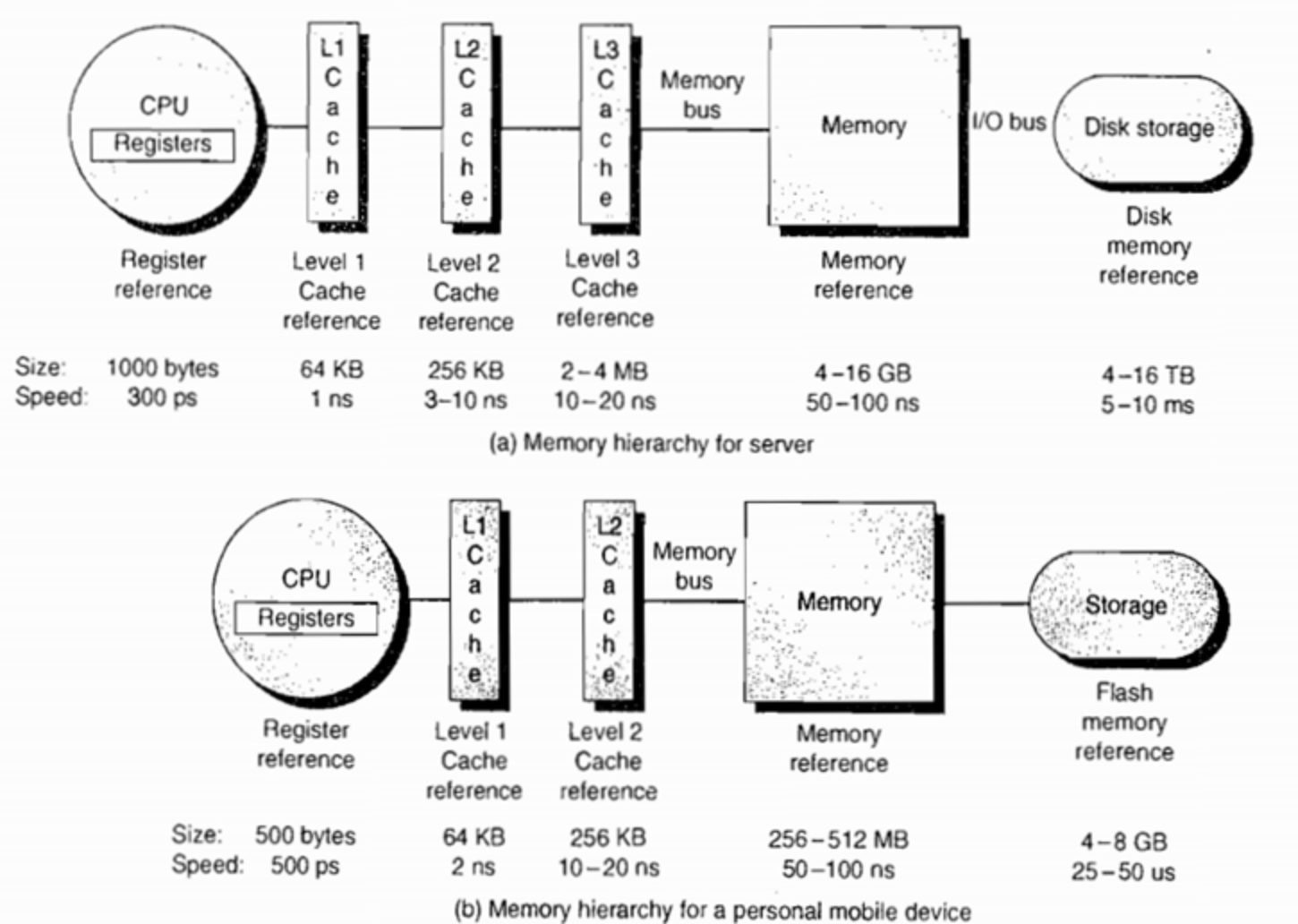
JVM在设计时候考虑到,如果JAVA线程每次读取和写入变量都直接操作主内存,对性能影响比较大,所以每条线程拥有各自的工作内存,工作内存中的变量是主内存中的一份拷贝,线程对变量的读取和写入,直接在工作内存中操作,而不能直接去操作主内存中的变量。但是这样就会出现一个问题,当一个线程修改了自己工作内存中变量,对其他线程是不可见的,会导致线程不安全的问题。因此 JMM 制定了 一套标准来保证开发者在编写多线程程序的时候,能够控制什么时候内存会被同步给其他线程。
JMM的内存模型
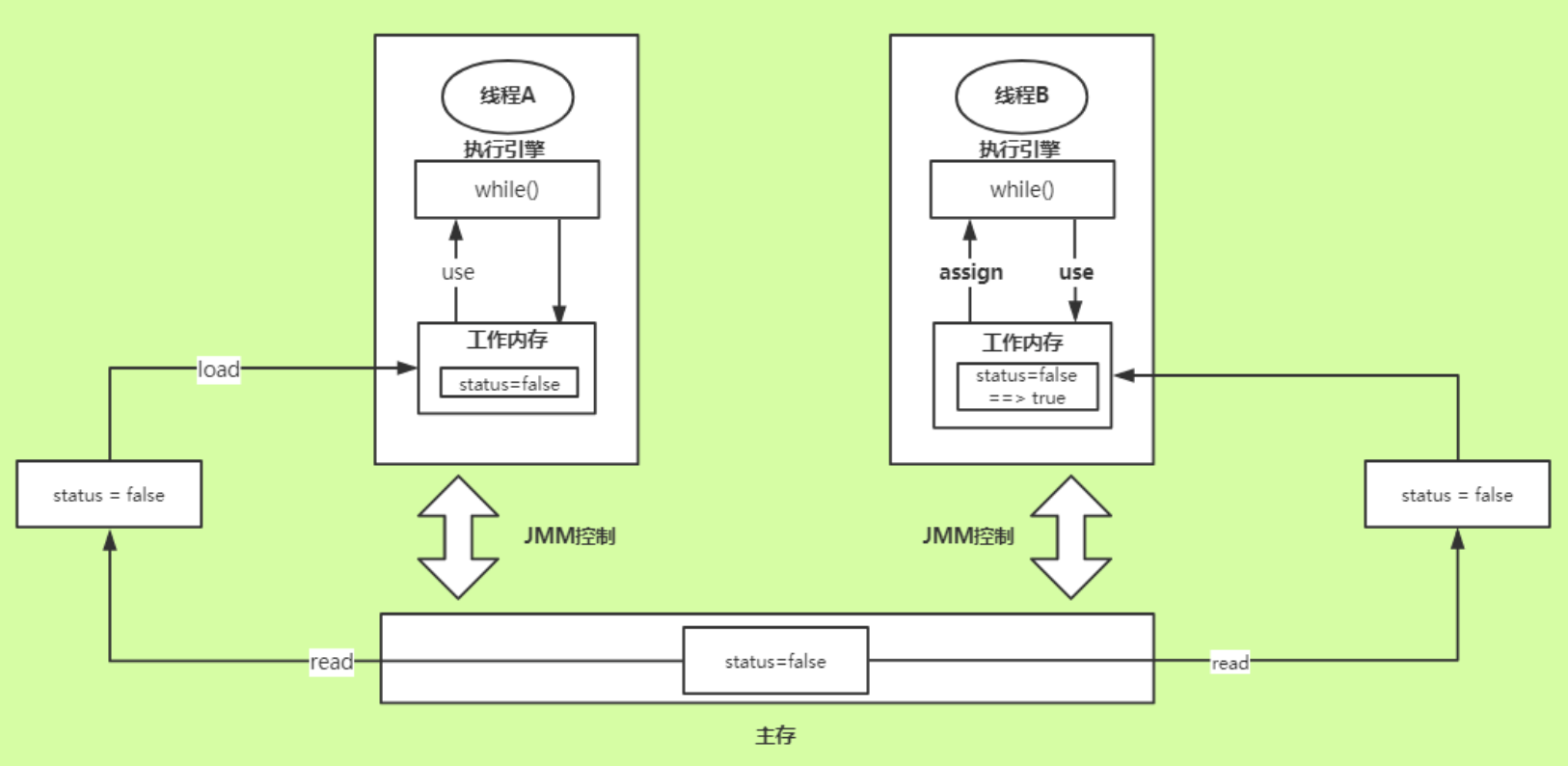
线程A感知不到线程B操作了值的变化!如何能够保证线程间可以同步感知这个问题呢?只需要使用 Volatile关键字即可!volatile 保证线程间变量的可见性,简单地说就是当线程A对变量X进行了修改后, 在线程A后面执行的其他线程能看到变量X的变动,更详细地说是要符合以下两个规则 :
- 线程对变量进行修改之后,要立刻回写到主内存。
- 线程对变量读取的时候,要从主内存中读,而不是缓存。
各线程的工作内存间彼此独立,互不可见,在线程启动的时候,虚拟机为每个内存分配一块工作内存, 不仅包含了线程内部定义的局部变量,也包含了线程所需要使用的共享变量(非线程内构造的对象)的副本,即,为了提高执行效率。
内存交互操作
内存交互操作有8种,虚拟机实现必须保证每一个操作都是原子的,不可在分的(对于double和long类型的变量来说,load、store、read和write操作在某些平台上允许例外)
- lock (锁定):作用于主内存的变量,把一个变量标识为线程独占状态
- unlock (解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read (读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load (载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中
- use (使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令
- assign (赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中
- store (存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用
- write (写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内 存的变量中
JMM对这八种指令的使用,制定了如下规则:
- 不允许read和load、store和write操作之一单独出现。即:使用了read必须load,使用了store必须 write
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
- 不允许一个线程将没有assign的数据从工作内存同步回主内存
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是对变量实施use、store操作之前,必须经过assign和load操作
- 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前, 必须重新load或assign操作初始化变量的值
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存
JMM对这八种操作规则和对volatile的一些特殊规则就能确定哪里操作是线程安全,哪些操作是线程不 安全的了。但是这些规则实在复杂,很难在实践中直接分析。所以一般我们也不会通过上述规则进行分 析。更多的时候,使用java的happen-before规则来进行分析。
- happens-before字面翻译过来就是先行发生,A happens-before B 就是A先行发生于B?
不准确!在Java内存模型中,happens-before 应该翻译成:前一个操作的结果可以被后续的操作获取。 讲白点就是前面一个操作把变量a赋值为1,那后面一个操作肯定能知道a已经变成了1。
我们再来看看为什么需要这几条规则?
因为我们现在电脑都是多CPU,并且都有缓存,导致多线程直接的可见性问题。
所以为了解决多线程的可见性问题,就搞出了happens-before原则,让线程之间遵守这些原则。编译器 还会优化我们的语句,所以等于是给了编译器优化的约束。不能让它优化的不知道东南西北了!
17、volatile
volatile是不错的机制,但是也不能保证原子性。
- 代码验证可见性
public class JMMVolatileDemo01 {
/**
* Volatile 用来保证数据的同步,也就是可见性
* 不加 volatile 就没有可见性,会一直循环
*/
private volatile static int num = 0;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (num == 0) {
}
}).start();
Thread.sleep(1000);
num = 1;
System.out.println(num);
}
}
- 验证 volatile 不保证原子性
原子性理解:不可分割,完整性,也就是某个线程正在做某个具体的业务的时候,中间不可以被加塞或者被分割,需要整体完整,要么同时成功,要么同时失败。
public class JMMVolatileDemo02 {
private volatile static int num = 0;
public static void add() {
num++;
}
// 结果应该是 num 为 2万,测试看结果
public static void main(String[] args) throws InterruptedException {
for (int i = 1; i <= 20; i++) {
new Thread(() -> {
for (int j = 1; j <= 1000; j++) {
add();
}
}, String.valueOf(i)).start();
}
// 需要等待上面20个线程都全部计算完毕,看最终结果
// 默认一个 main线程 一个 gc 线程
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + " " + num);
}
}
为我们的 add 方法没有加锁,加了 volatile ,说明 volatile 不能保证原子性;
命令行查看底层字节码代码: javap -c JMMVolatileDemo02.class
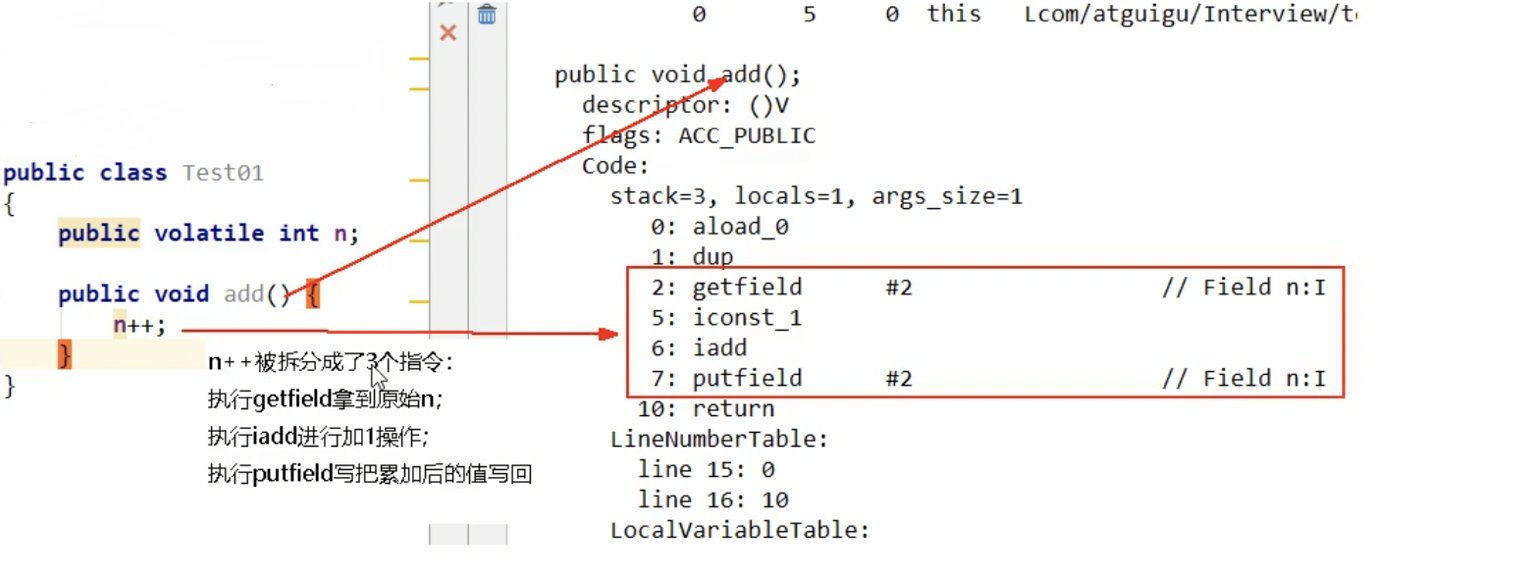
num++ 在多线程下是非线程安全的,如何不加 synchronized解决?
查看原子包下的类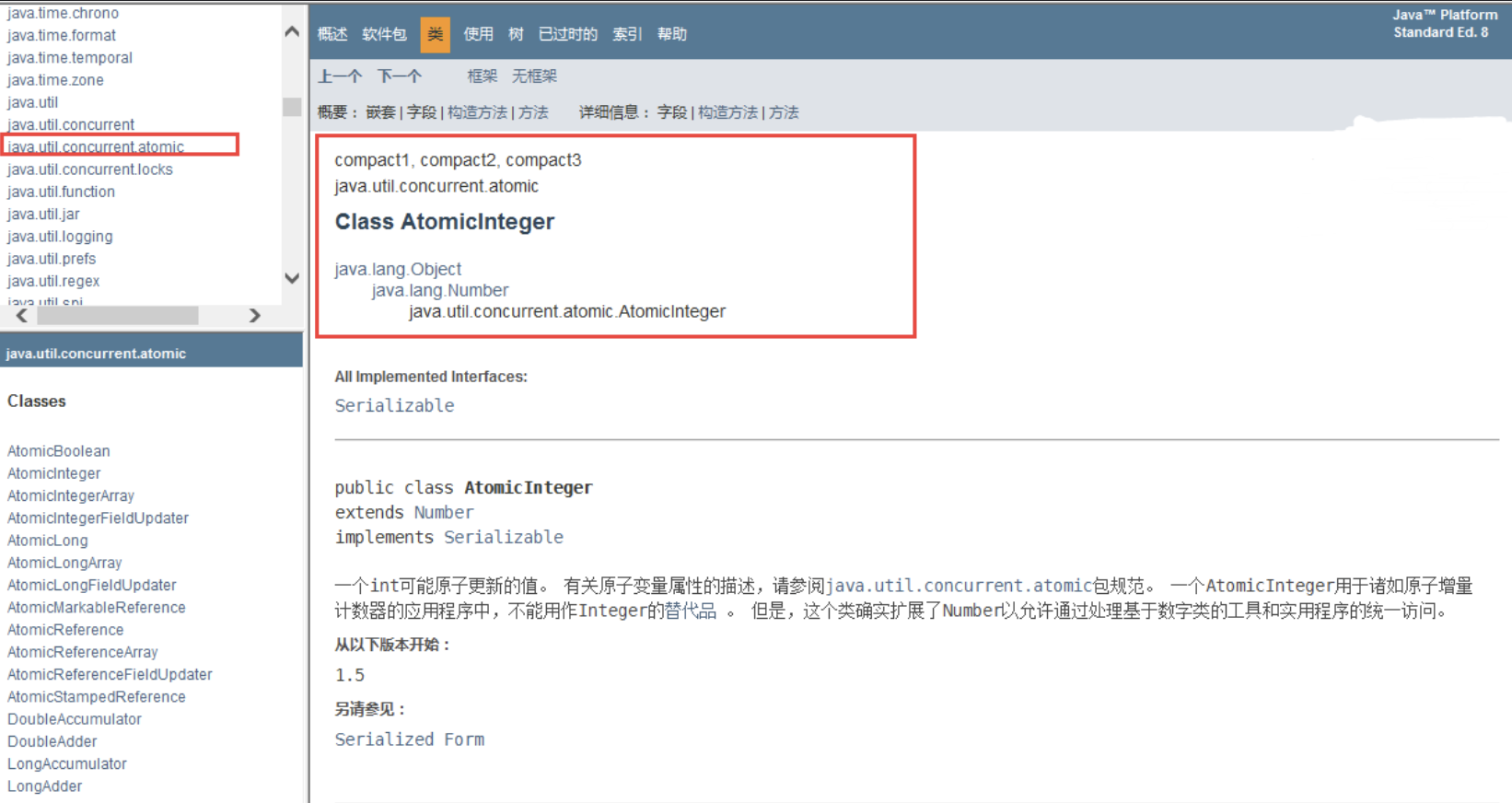
public class JMMVolatileDemo02 {
private volatile static AtomicInteger num = new AtomicInteger();
public static void add() {
num.getAndIncrement(); // 等价 num++
}
// 结果应该是 num 为 2万,测试看结果
public static void main(String[] args) throws InterruptedException {
for (int i = 1; i <= 20; i++) {
new Thread(() -> {
for (int j = 1; j <= 1000; j++) {
add();
}
}, String.valueOf(i)).start();
}
// 需要等待上面20个线程都全部计算完毕,看最终结果
// 默认一个 main线程 一个 gc 线程
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + " " + num);
}
}
指令重排
计算机在执行程序时,为了提高性能,编译器和处理器的常常会对指令做重排

一般分以下3种问题:
单线程环境里面确保程序最终执行结果和代码顺序执行的结果一致。
处理器在进行重排序时必须要考虑指令之间的数据依赖性。
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
指令重排是什么
指令队列在CPU执行时不是串行的, 当某条指令执行时消耗较多时间时, CPU资源足够时并不会在此无意义的等待, 而是开启下一个指令. 开启下一条指令是有条件的, 即上一条指令和下一条指令不存在相关性. 例如下面这个例子:
a /= 2; // 指令A
a /= 2; // 指令B
c++; // 指令C
里的指令B是依赖于指令A的执行结果的, 在A处于执行阶段时, B会被阻塞, 直到A执行完成. 而指令C与A/B均没有依赖关系, 所以在A执行或者B执行的过程中, C会同时被执行, 那么C有可能在A+B的执行过程中就执行完毕了, 这样指令队列的实际执行顺序就是 C->A->B 或者 A->C->B.

指令重排小结:
volatile 实现了禁止指令重排优化,从而避免多线程环境下程序出现乱序执行的现象
先了解一个概念,内存屏障(Memory Barrier)又称内存栅栏,是一个CPU 指令,它的作用有两个:
1、保证特定操作的执行顺序。
2、保证某些变量的内存可见性(利用该特性实现volatile的内存可见性)。
由于编译器和处理器都能执行指令重排优化。如果在指令间插入一条 Memory Barrier 则会告诉编译器和CPU,不管什么指令都不能和这条 Memory Barrier 指令重排序,也就是说,通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化。内存屏障另外一个作用是强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本。

经过,可见性,原子性,指令重排的话,线程安全性获得保证:
对于指令重排导致的可见性问题 和 有序性问题,可以利用 volatile 关键字解决,因为 volatile 的另外一 个作用就是禁止重排序优化。
18、单例模式
如何防止反射 破坏单例模式?
推荐阅读:单例模式 | 菜鸟教程
饿汉式
public class Hungry {
private Hungry() {
}
private final static Hungry hungry = new Hungry();
public static Hungry getInstance() {
return hungry;
}
}
饿汉式是最简单的单例模式的写法,保证了线程的安全
但饿汉式会有一点小问题,看下面的代码:
public class Hungry {
private byte[] data1 = new byte[1024];
private byte[] data2 = new byte[1024];
private byte[] data3 = new byte[1024];
private byte[] data4 = new byte[1024];
private Hungry() {
}
private final static Hungry hungry = new Hungry();
public static Hungry getInstance() {
return hungry;
}
}
在 Hungry 类中,我定义了四个byte数组,当代码一运行,这四个数组就被初始化,并且放入内存了,如果长时间没有用到getInstance方法,不需要Hungry类的对象,这不是一种浪费吗?我希望的是只有用 到了 getInstance 方法,才会去初始化单例类,才会加载单例类中的数据。所以就有了第二种单例模式:懒汉式
懒汉式
public class LazyMan {
private LazyMan() {
System.out.println(Thread.currentThread().getName() + "Start");
}
private static LazyMan lazyMan;
public static LazyMan getInstance() {
if (lazyMan == null) {
lazyMan = new LazyMan();
}
return lazyMan;
}
// 测试并发环境,发现单例失效
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
LazyMan.getInstance();
}).start();
}
}
}
多加一层检测可以避免问题,也就是DCL懒汉式!
public class LazyMan {
private LazyMan() {
}
private static LazyMan lazyMan;
public static LazyMan getInstance() {
if (lazyMan == null) {
synchronized (LazyMan.class) {
if (lazyMan == null) {
lazyMan = new LazyMan();
}
}
}
return lazyMan;
}
}
DCL懒汉式的单例,保证了线程的安全性,又符合了懒加载,只有在用到的时候,才会去初始化,调用 效率也比较高,但是这种写法在极端情况还是可能会有一定的问题。
因为 lazyMan = new LazyMan(); 不是原子性操作,至少会经过三个步骤:
- 分配对象内存空间
- 执行构造方法初始化对象
- 设置instance指向刚分配的内存地址,此时 instance !=null;
由于指令重排,导致A线程执行 lazyMan = new LazyMan(); 的时候,可能先执行了第三步(还没执行第 二步),由于线程调度,当线程B进来时,发现 lazyMan 已经不为空了,直接返回了lazyMan,并且后面使用了返回的lazyMan,由于线程A还没有执行第二步,导致此时lazyMan还不完整,可能会有一些意想不到的错误,所以就有了下面一种单例模式。
这种单例模式只是在上面DCL单例模式增加一个volatile关键字来避免指令重排:
public class LazyMan {
private LazyMan() {
}
private volatile static LazyMan lazyMan;
public static LazyMan getInstance() {
if (lazyMan == null) {
synchronized (LazyMan.class) {
if (lazyMan == null) {
lazyMan = new LazyMan();
}
}
}
return lazyMan;
}
}
静态内部类
还有这种方式是第一种饿汉式的改进版本,同样也是在类中定义static变量的对象,并且直接初始化,不 过是移到了静态内部类中,十分巧妙。既保证了线程的安全性,同时又满足了懒加载。
public class Holder {
private Holder() {
}
public static Holder getInstance() {
return InnerClass.holder;
}
private static class InnerClass {
private static final Holder holder = new Holder();
}
}
万恶的反射
万恶的反射登场了,反射是一个比较霸道的东西,无视private修饰的构造方法,可以直接在外面 newInstance,破坏我们辛辛苦苦写的单例模式。
public class SingletonPatternDemo {
public static void main(String[] args) throws Exception {
LazyMan lazyMan1 = LazyMan.getInstance();
Constructor<LazyMan> declaredConstructor = LazyMan.class.getDeclaredConstructor(null);
declaredConstructor.setAccessible(true);
LazyMan lazyMan2 = declaredConstructor.newInstance();
System.out.println(lazyMan1.hashCode());
System.out.println(lazyMan2.hashCode());
}
}
我们分别打印出lazyMan1,lazyMan2的hashcode,发现不相等
那么,怎么解决这种问题呢?
在私有的构造函数中做一个判断,如果lazyMan不为空,说明lazyMan已经被创建过了,如果正常调用 getInstance方法,是不会出现这种事情的,所以直接抛出异常!
public class LazyMan {
private LazyMan() {
synchronized (LazyMan.class) {
if (lazyMan != null) {
throw new RuntimeException("不要试图用反射破坏单例模式");
}
}
}
private static LazyMan lazyMan;
public static LazyMan getInstance() {
if (lazyMan == null) {
synchronized (LazyMan.class) {
if (lazyMan == null) {
lazyMan = new LazyMan();
}
}
}
return lazyMan;
}
}
但是这种写法还是有问题:
上面我们是先正常的调用了getInstance方法,创建了LazyMan对象,所以第二次用反射创建对象,私有构造函数里面的判断起作用了,反射破坏单例模式失败。但是如果破坏者干脆不先调用getInstance方 法,一上来就直接用反射创建对象,我们的判断就不生效了:
那么如何防止这种反射破坏呢?
public class LazyMan {
private static boolean flag = false;
private LazyMan() {
synchronized (LazyMan.class) {
if (flag == false) {
flag = true;
} else {
throw new RuntimeException("不要试图用反射破坏单例模式");
}
}
}
private static LazyMan lazyMan;
public static LazyMan getInstance() {
if (lazyMan == null) {
synchronized (LazyMan.class) {
if (lazyMan == null) {
lazyMan = new LazyMan();
}
}
}
return lazyMan;
}
}
在这里,我定义了一个boolean变量flag,初始值是false,私有构造函数里面做了一个判断,如果 flag=false,就把flag改为true,但是如果flag等于true,就说明有问题了,因为正常的调用是不会第二 次跑到私有构造方法的,所以抛出异常。
看起来很美好,但是还是不能完全防止反射破坏单例模式,因为可以利用反射修改flag的值。
public class SingletonPatternDemo {
public static void main(String[] args) throws Exception {
Constructor<LazyMan> declaredConstructor = LazyMan.class.getDeclaredConstructor(null);
Field field = LazyMan.class.getDeclaredField("flag");
field.setAccessible(true);
// 通过反射实例化对象
declaredConstructor.setAccessible(true);
LazyMan lazyMan1 = declaredConstructor.newInstance();
System.out.println(field.get(lazyMan1));
System.out.println(lazyMan1.hashCode());
//通过反射,修改字段的值!
field.set(lazyMan1, false);
LazyMan lazyMan2 = declaredConstructor.newInstance();
System.out.println(field.get(lazyMan2));
System.out.println(lazyMan2.hashCode());
}
}
并没有一个很好的方案去避免反射破坏单例模式,所以轮到我们的枚举登场了。
枚举
枚举类型是Java 5中新增特性的一部分,它是一种特殊的数据类型,之所以特殊是因为它既是一种类 (class)类型却又比类类型多了些特殊的约束,但是这些约束的存在也造就了枚举类型的简洁性、安全性 以及便捷性。
public enum EnumSingleton {
INSTANCE;
public EnumSingleton getInstance(){
return INSTANCE;
}
}
枚举是目前最推荐的单例模式的写法,因为足够简单,不需要开发自己保证线程的安全,同时又可以有 效的防止反射破坏我们的单例模式
19、CAS
CAS(Conmpare And Swap) : 比较和交换
JAVA1.5开始引入了CAS,主要代码都放在JUC的atomic包下
public class CASDemo {
public static void main(String[] args) {
//真实值为 5
AtomicInteger atomicInteger = new AtomicInteger(5);
// 期望的是5,后面改为 2020 , 所以结果为 true,2020
atomicInteger.compareAndSet(5, 2020);
System.out.println(atomicInteger.get());
// 期望的是5,后面改为 1024 , 所以结果为 false,2020
System.out.println(atomicInteger.compareAndSet(5, 1024) + "=>" + atomicInteger.get());
}
}
真实值和期望值相同,就修改成功,真实值和期望值不同,就修改失败!
分析源码,如何实现的 i++ 安全的问题:atomicInteger.getAndIncrement();
public final int getAndIncrement() {
// this 当前对象
// valueOffset 内存偏移量,内存地址
// 1 固定写死
return unsafe.getAndAddInt(this, valueOffset, 1);
}
跳转到 unsafe
且这个类中的方法大部分都是 native 的方法了!
- 问题:这个UnSafe类到底是什么?
1、UnSafe
UnSafe是 CAS 的核心类,由于Java方法无法直接访问底层系统,需要通过本地(native)方法来访问, UnSafe相当于一个后门,基于该类可以直接操作特定内存的数据,Unsafe类存在于 sun.misc 包中,其内部方法操作可以像C的指针一样直接操作内存,因为Java中CAS操作的执行依赖于Unsafe类的方法。
2、变量valueOffset
表示该变量值在内存中的偏移地址,因为Unsafe就是根据内存偏移地址获取数据的
3、变量 value用volatile修饰,保证了多线程之间的内存可见性
最后解释CAS 是什么
CAS 的全称为 Compare-And-Swap,它是一条CPU并发原语。
它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的。
CAS并发原语体现在JAVA语言中就是 sun.misc.Unsafe 类中的各个方法。调用 UnSafe类中的 CAS 方法, JVM会帮我们实现出CAS汇编指令。这是一种完全依赖于硬件的功能,通过它实现了原子操作。再次强调,由于CAS是一种系统原语,原语属于操作系统用于范畴,是由若干条指令组成的,用于完成某个功 能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条 CPU 的原子指令,不会造成所谓的数据不一致问题。
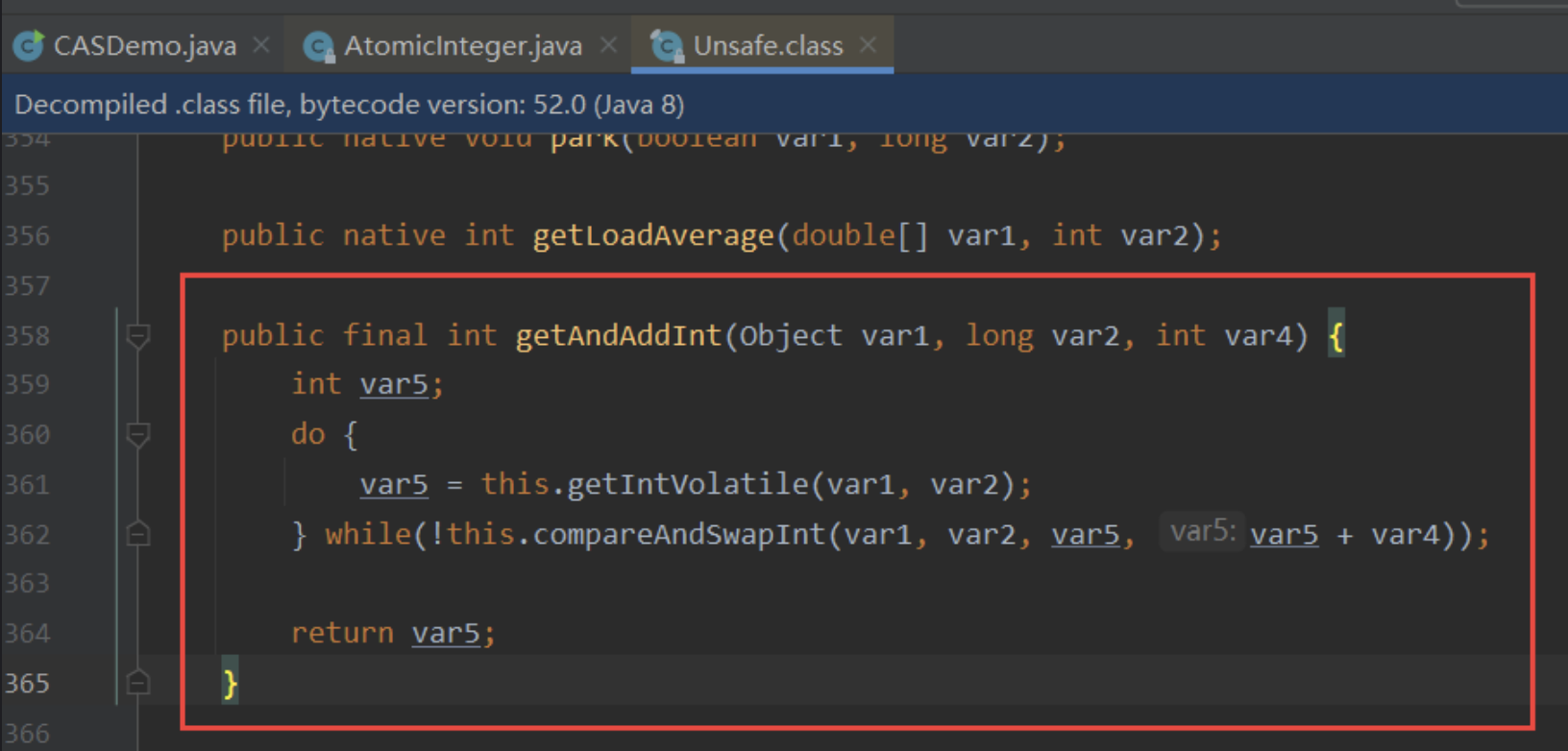
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
// 获取传入对象的地址
var5 = this.getIntVolatile(var1, var2);
// 比较并交换,如果var1,var2 还是原来的 var5,就执行内存偏移+1; var5 +var4
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
汇编层面理解
Unsafe 类中的 compareAndSwapint,是一个本地方法,该方法的实现位于 unsafe.cpp 中;

总结
CAS(CompareAndSwap):
比较当前工作内存中的值和主内存中的值,如果相同则执行规定操作,否则继续比较直到主内存和工作内存中的值一致为止。
CAS 应用:
CAS 有3个操作数,内存值V,旧的预期值A,要修改的更新值B。且仅当预期值A 和 内存值 V 相同时, 将内存值 V 修改为B,否则什么都不做。
CAS 的缺点:
1、循环时间长开销很大。
可以看到源码中存在 一个 do…while 操作,如果CAS失败就会一直进行尝试。
2、只能保证一个共享变量的原子操作。
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作。但是,对多个共享变量操作时,循环CAS就无法保证操作的原子性,这时候就可以用锁来保证原子性
3、CAS实现的过程是先取出内存中某时刻的数据,在下一时刻比较并替换,那么在这个时间差会导致数据的变化,此时就会导致出现“ABA”问题
什么是”ABA”问题?
比如说一个线程one从内存位置V中取出A,这时候另一个线程two也从内存中取出A,并且two进行了一些操作变成了B,然后two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后one操作成功。
尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的。
20、原子引用
demo:
public class AtomicReferenceDemo {
public static void main(String[] args) {
User zhangsan = new User("zhangsan", 22);
User lisi = new User("lisi", 25);
AtomicReference<User> atomicReference = new AtomicReference<>();
atomicReference.set(zhangsan); // 设置
// 期望的是zhangsan,后面改为 lisi , 所以结果为 true,
System.out.print(atomicReference.compareAndSet(zhangsan, lisi)+"=>");
System.out.println(atomicReference.get().toString());
// 期望的是zhangsan,后面改为 lisi , 所以结果为 flase,
System.out.print(atomicReference.compareAndSet(zhangsan, lisi));
System.out.println(atomicReference.get().toString());
}
}
原子引用 AtomicReference 解决ABA问题
要解决ABA问题,我们就需要加一个版本号
版本号原子引用,类似乐观锁
public class ABASaveDemo {
static AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(100, 1);
public static void main(String[] args) {
new Thread(() -> {
int stamp = atomicStampedReference.getStamp(); // 获得版本号
System.out.println("T1 stamp 01=>" + stamp);
// 暂停2秒钟,保证下面线程获得初始版本号
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
atomicStampedReference.compareAndSet(100, 101,
atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1);
System.out.println("T1 stamp 02=>" + atomicStampedReference.getStamp());
atomicStampedReference.compareAndSet(101, 100,
atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1);
System.out.println("T1 stamp 03=>" + atomicStampedReference.getStamp());
}, "T1").start();
new Thread(() -> {
int stamp = atomicStampedReference.getStamp(); // 获得版本号
System.out.println("T2 stamp 01=>" + stamp);
// 暂停3秒钟,保证上面线程先执行
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
boolean result = atomicStampedReference.compareAndSet(100, 2019,
stamp, stamp + 1);
System.out.println("T2 是否修改成功 =>" + result);
System.out.println("T2 最新stamp =>" + atomicStampedReference.getStamp());
System.out.println("T2 当前的最新值 =>" + atomicStampedReference.getReference());
}, "T2").start();
}
}
21、Java锁
公平锁非公平锁
公平锁:是指多个线程按照申请锁的顺序来获取锁,类似排队打饭,先来后到。
非公平锁:是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比现申请的线程优先获取锁,在高并发的情况下,有可能会造成优先级反转或者饥饿现象。
// 无参
public ReentrantLock() {
sync = new NonfairSync();
}
// 有参
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
两者区别
并发包中的 ReentrantLock 的创建可以指定构造函数的 boolean 类型来得到公平锁或者非公平锁,默认是非公平锁!
公平锁:就是很公平,在并发环境中,每个线程在获取到锁时会先查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一个,就占有锁,否则就会加入到等待队列中,以后会按照FIFO的规则从队列中取到自己。
非公平锁:非公平锁比较粗鲁,上来就直接尝试占有锁,如果尝试失败,就会采用类似公平锁那种方式。
Java ReentrantLock 而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在 于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁。
可重入锁
可重入锁(也叫递归锁)
指的是同一线程外层函数获得锁之后,内层递归函数仍然能获取该锁的代码,在同一个线程在外层方法 获取锁的时候,在进入内层方法会自动获取锁。
也就是说,线程可以进入任何一个它已经拥有的锁,所同步着的代码块。 好比家里进入大门之后,就可以进入里面的房间了;
ReentrantLock、Synchronized 就是一个典型的可重入锁;
可重入锁最大的作用就是避免死锁
测试一:Synchronized
public class ReentrantLockDemo {
public static void main(String[] args) {
Phone phone = new Phone();
// T1 线程在外层获取锁时,也会自动获取里面的锁
new Thread(() -> {
phone.sendSMS();
}, "T1").start();
new Thread(() -> {
phone.sendSMS();
}, "T2").start();
}
}
class Phone {
public synchronized void sendSMS() {
System.out.println(Thread.currentThread().getName() + " sendSMS");
sendEmail();
}
public synchronized void sendEmail() {
System.out.println(Thread.currentThread().getName() + " sendEmail");
}
}
测试二:ReentrantLock
public class ReentrantLockDemo {
public static void main(String[] args) {
Phone phone = new Phone();
// T1 线程在外层获取锁时,也会自动获取里面的锁
new Thread(phone, "T1").start();
new Thread(phone, "T2").start();
}
}
class Phone implements Runnable {
Lock lock = new ReentrantLock();
@Override
public void run() {
get();
}
public void get() {
lock.lock();
// lock.lock(); 锁必须匹配,如果两个锁,只有一个解锁就会失败
try {
System.out.println(Thread.currentThread().getName() + " get()");
set();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
// lock.lock();
}
}
public void set() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " set()");
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
自旋锁
自旋锁(spinlock),是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
public class SpinLockDemo {
// 原子引用线程, 没写参数,引用类型默认为null
AtomicReference<Thread> atomicReference = new AtomicReference<>();
//上锁
public void myLock() {
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName() + "==>mylock");
// 自旋
while (!atomicReference.compareAndSet(null, thread)) {
}
}
//解锁
public void myUnlock() {
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread, null);
System.out.println(Thread.currentThread().getName() + "==>myUnlock");
}
public static void main(String[] args) throws InterruptedException {
SpinLockDemo spinLockDemo = new SpinLockDemo();
new Thread(() -> {
spinLockDemo.myLock();
try {
TimeUnit.SECONDS.sleep(4);
} catch (InterruptedException e) {
e.printStackTrace();
}
spinLockDemo.myUnlock();
}, "T1").start();
TimeUnit.SECONDS.sleep(1);
new Thread(() -> {
spinLockDemo.myLock();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
spinLockDemo.myUnlock();
}, "T2").start();
}
}
死锁
死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力干涉那它们都将无法推进下去,如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否者就会因为争夺有限的资源而陷入死锁。
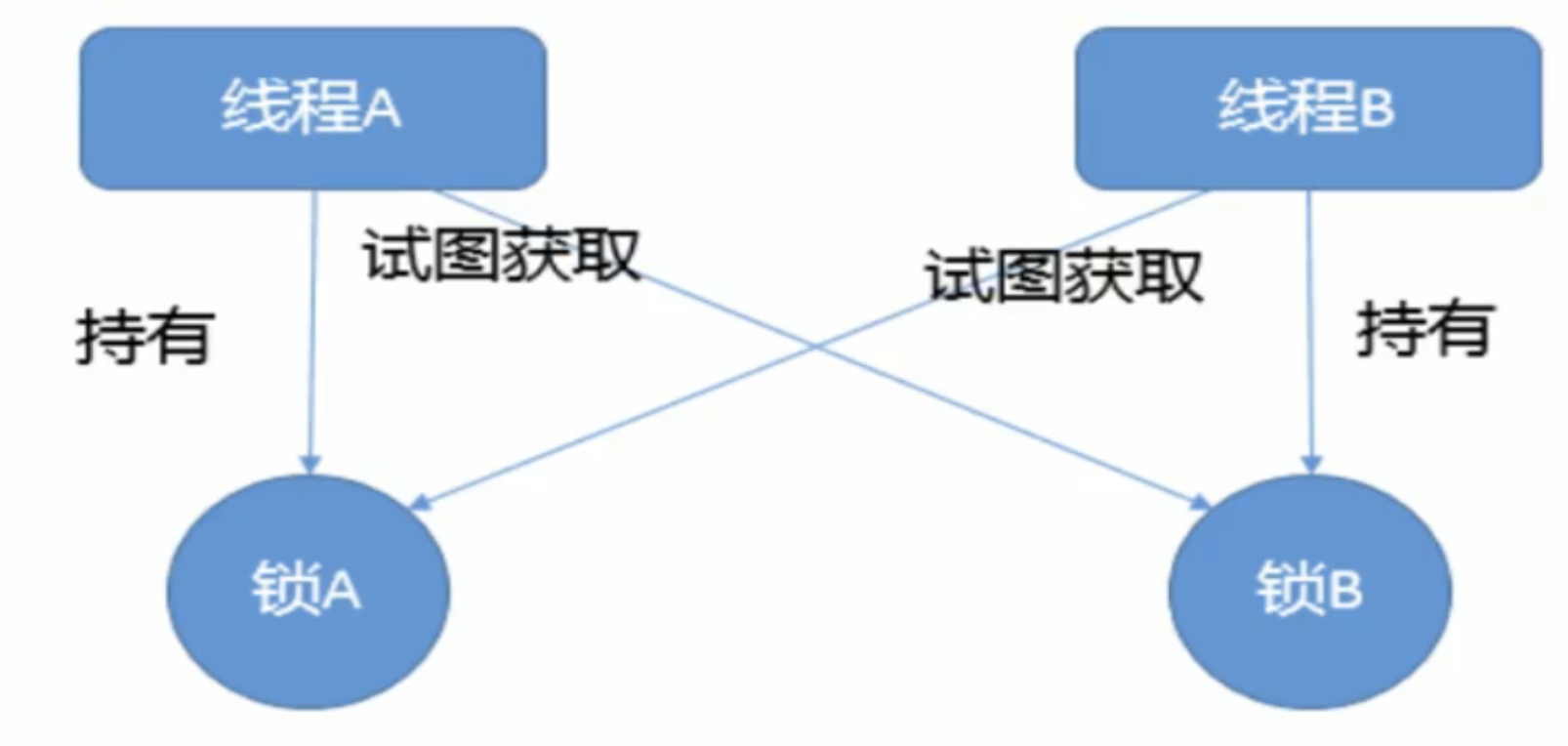
产生死锁主要原因:
1、系统资源不足
2、进程运行推进的顺序不合适
3、资源分配不当
测试:
public class DeadLockDemo {
public static void main(String[] args) {
String lockA = "lockA";
String lockB = "lockB";
new Thread(new HoldLockThread(lockA, lockB), "T1").start();
new Thread(new HoldLockThread(lockB, lockA), "T2").start();
}
}
class HoldLockThread implements Runnable {
private String lockA;
private String lockB;
public HoldLockThread(String lockA, String lockB) {
this.lockA = lockA;
this.lockB = lockB;
}
@Override
public void run() {
synchronized (lockA) {
System.out.println(Thread.currentThread().getName() + "lock:" + lockA + "=>get" + lockB);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lockB) {
System.out.println(Thread.currentThread().getName() + "lock:" + lockB + "=>get" + lockA);
}
}
}
}
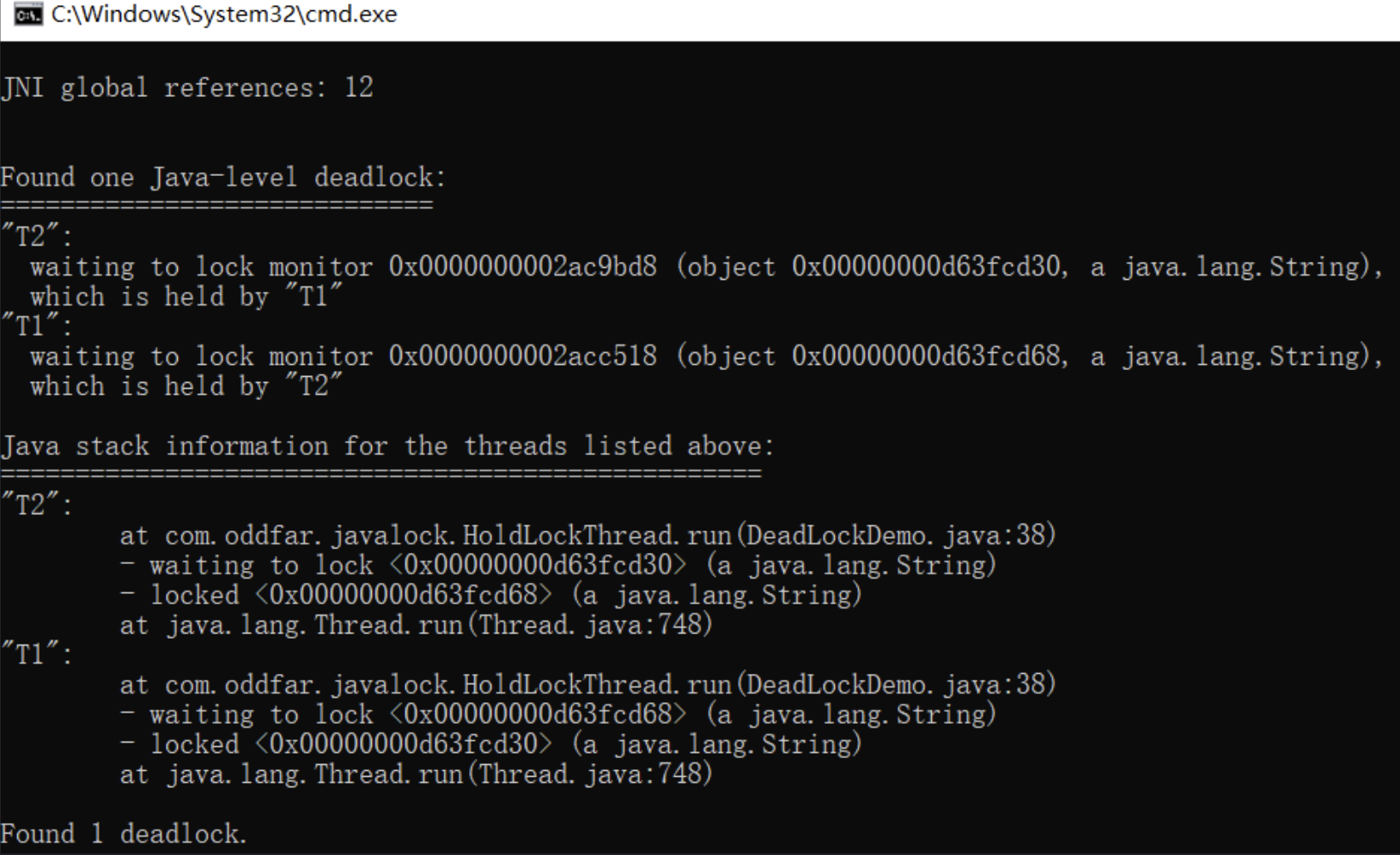
解决
1、查看JDK目录的bin目录
2、使用 jps -l 命令定位进程号
3、使用 jstack 进程号 找到死锁查看
评论