
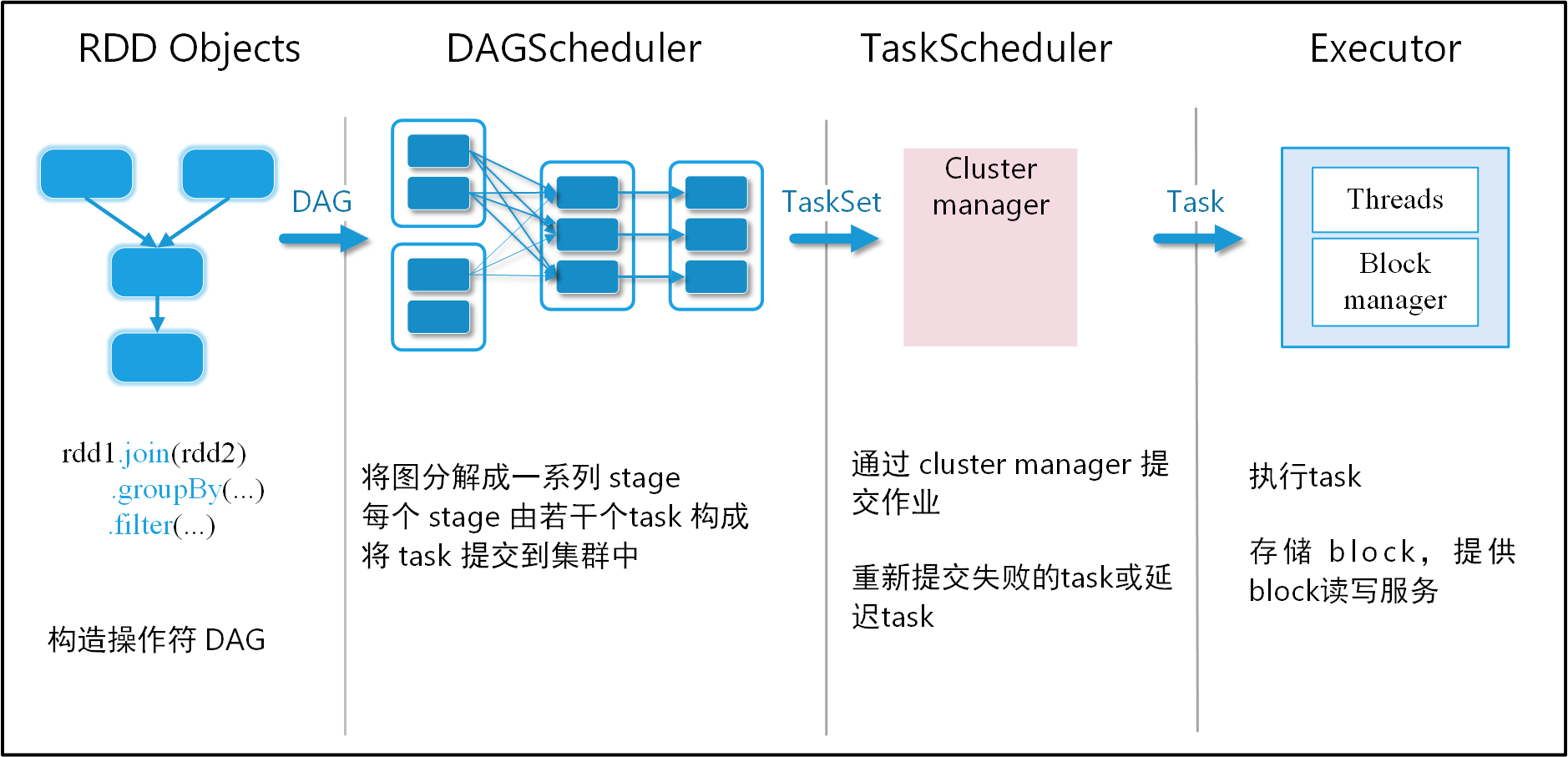
1、在命令行执行提交命令时,在spark-submit脚本中,调用了SparkSubmit类中的mainMethod.invoke方法,这个类通过反射,调用我们自定义的类。
2、我们自定义类中的main方法开始执行,初始化了SparkConf和SparkContext,将 Driver 启动起来,同时构造出来DAGScheduler和TaskScheduler。
3、Driver端会对我们的代码进行解析,执行到 Action 算子,这个阶段会产生 DAG 血缘依赖关系,但是并没有真正执行,
4、执行 Action 算子,当程序触发action算子的时候就会产生一个job,会调用DAGScheduler中的runjob方法来提交任务。
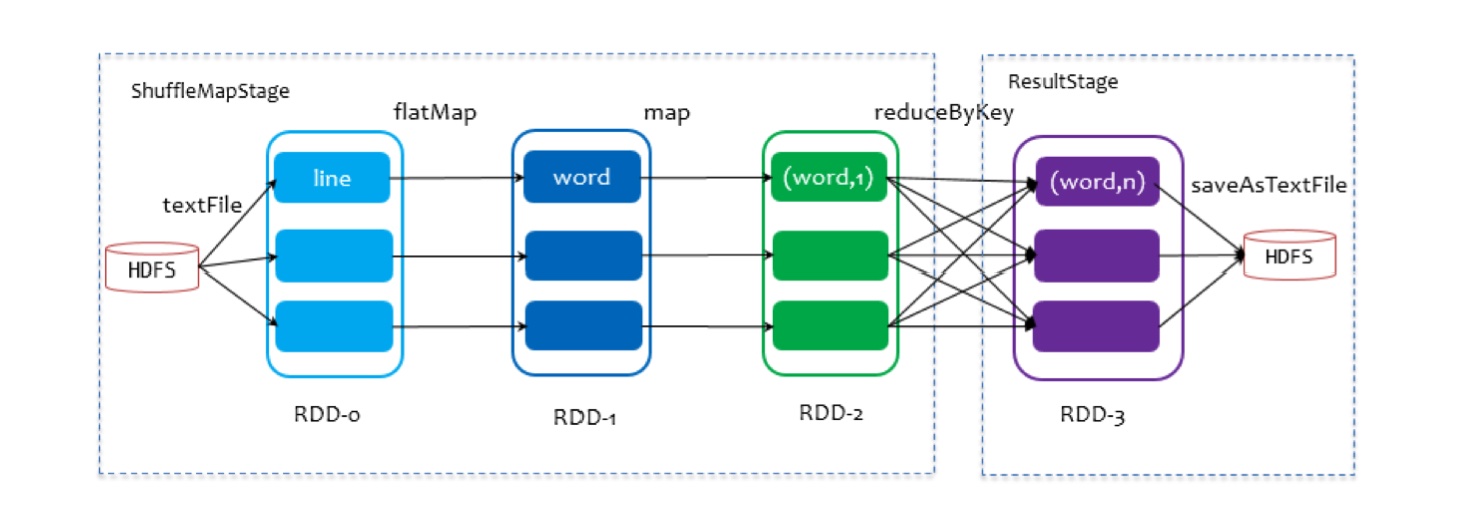
5、DAGScheduler 会对提交的 Job 进行 Stage 切分 (程序会拿到最后一个rdd(finalRDD)来创建一个ResultStage,得到ResultStage之后,就正式的开始切分stage,从后往前遍历,一旦遇到窄依赖,就把rdd加入到当前的stage中,一旦遇到宽依赖,就会结束当前的stage,重新起动一个新的ShuffleMapStage。继续往前遍历,一直到rdd已经没有父依赖,整个切分结束)。
6、当切分完了stage之后,就开始调用submitStage提交stage(从最后一个ResultStage开始触发提交,进行深度优先遍历,从前向后提交)。
7、将stage调用模式匹配生成不同的task(程序会根据提交stage的不同,调用模式匹配生成ShuffleMapTask和ResultTask)。DagScheduler把当前提交的stage中的这么一些功能相同,处理的数据不同的task,组装成TaskSet,将TaskSet发送给TaskScheduler。
8、TaskScheduler会把TaskSet解压,生成task,然后把task进行序列化。
9、TaskSchedule向Master注册Application,申请资源。
10、Master收到Application的注册请求后,会根据自己的资源调度算法,在spark集群的worker上启动一个或多个Executor进程。
11、TaskScheduler会把序列化好的task递交到Executor上面,Executor将task放入线程池进行运行。
12、执行结束后,将执行结果反馈给Driver 端,然后进行资源注销。
评论