
说明:本系列笔记总结自
雷丰阳老师教学项目《谷粒商城》
- 视频地址:直达BiliBili
- 完整项目地址:直达gitee
- 本篇主要对应代码: gitee地址
- 项目资料获取:
在查阅本篇之前,这些前置工作是要有的
一、ElasticSearch简介
1.1 什么是ElasticSearch
The Elastic Stack,包括 Elasticsearch、 Kibana、 Beats 和 Logstash(也称为 ELK Stack)。
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.2 全文搜索引擎
Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录量达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。
为了解决结构化数据搜索和非结构化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎
这里说到的全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
1.3 Elasticsearch And Solr
Lucene 是 Apache 软件基金会 Jakarta 项目组的一个子项目,提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的免费开源工具。就其本身而言, Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。
但 Lucene 只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来进行应用。
目前市面上流行的搜索引擎软件,主流的就两款: Elasticsearch 和 Solr,这两款都是基于 Lucene 搭建的,可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者除了服务器安装、部署、管理、集群以外,对于数据的操作 修改、添加、保存、查询等等都十分类似。
在使用过程中,一般都会将 Elasticsearch 和 Solr 这两个软件对比,然后进行选型。这两个搜索引擎都是流行的,先进的的开源搜索引擎。它们都是围绕核心底层搜索库 - Lucene构建的 - 但它们又是不同的。像所有东西一样,每个都有其优点和缺点:
1.4 Elasticsearch Or Solr
Elasticsearch 和 Solr 都是开源搜索引擎,那么我们在使用时该如何选择呢?
- Google 搜索趋势结果表明,与 Solr 相比, Elasticsearch 具有很大的吸引力,但这并不意味着 Apache Solr 已经死亡。虽然有些人可能不这么认为,但 Solr 仍然是最受欢迎的搜索引擎之一,拥有强大的社区和开源支持。
- 与 Solr 相比, Elasticsearch 易于安装且非常轻巧。但是,如果 Elasticsearch 管理不当,这种易于部署和使用可能会成为一个问题。基于 JSON 的配置很简单,但如果要为文件中的每个配置指定注释,那么它不适合您。总的来说,如果你的应用使用的是 JSON,那么 Elasticsearch 是一个更好的选择。
- 否则,请使用 Solr,因为它的 schema.xml 和 solrconfig.xml 都有很好的文档记录。
- Solr 拥有更大,更成熟的用户,开发者和贡献者社区。 ES 虽拥有的规模较小但活跃的用户社区以及不断增长的贡献者社区。
Solr 贡献者和提交者来自许多不同的组织,而 Elasticsearch 提交者来自单个公司。 - Solr 更成熟,但 ES 增长迅速,更稳定。
- Solr 是一个非常有据可查的产品,具有清晰的示例和 API 用例场景。 Elasticsearch 的文档组织良好,但它缺乏好的示例和清晰的配置说明。
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
那么,到底是 Solr 还是 Elasticsearch?
有时很难找到明确的答案。无论您选择 Solr 还是 Elasticsearch,首先需要了解正确的用例和未来需求。总结他们的每个属性。
- 由于易于使用, Elasticsearch 在新开发者中更受欢迎。一个下载和一个命令就可以启动一切。
- 如果除了搜索文本之外还需要它来处理分析查询, Elasticsearch 是更好的选择
- 如果需要分布式索引,则需要选择 Elasticsearch。对于需要良好可伸缩性和以及性能分布式环境, Elasticsearch 是更好的选择。
- Elasticsearch 在开源日志管理用例中占据主导地位,许多组织在 Elasticsearch 中索引它们的日志以使其可搜索。
- 如果你喜欢监控和指标,那么请使用 Elasticsearch,因为相对于 Solr, Elasticsearch 暴露了更多的关键指标
1.5 Elasticsearch 应用案例
- GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 “GitHub 使用
Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。 - 维基百科:启动以 Elasticsearch 为基础的核心搜索架构
- SoundCloud: “SoundCloud 使用 Elasticsearch 为 1.8 亿用户提供即时而精准的音乐搜索服务”。
- 百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器, 200 个 ES 节点,每天导入 30TB+数据。
- 新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
- 阿里:使用 Elasticsearch 构建日志采集和分析体系。
- Stack Overflow:解决 Bug 问题的网站,全英文,编程人员交流的网站。
二、ES相关概念(术语)
2.1 索引 index
类比mysql的数据库
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:新华字典前面的目录就是索引的意思,目录可以提高查询速度。
Elasticsearch 索引的精髓:一切设计都是为了提高搜索的性能。
2.2 类型 type
类别mysql的table
8版本已抛弃

在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。
比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
| 版本 | Type |
|---|---|
| 5.x | 支持多种 type |
| 6.x | 只能有一种 type |
| 7.x | 默认不再支持自定义索引类型(默认类型为: _doc) |
2.3 字段 Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
2.4 映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
2.5 文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。
注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
2.6 接近实时 NRT
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
2.7 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
2.8 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
2.9 分片shards
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
一个Elasticsearch 索引 是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
分片很重要,主要有两方面的原因:
- 1)允许你水平分割/扩展你的内容容量。
- 2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
副本(Replicas)
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。(存疑是5还是2)
2.10 倒排索引
一切设计都是为了提高搜索的性能
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
先来回忆一下我们是怎么插入一条索引记录的:
curl -X PUT "localhost:9200/user/_doc/1" -H 'Content-Type: application/json' -d'
{
"name" : "Jack",
"gender" : 1,
"age" : 20
}
其实就是直接PUT一个JSON的对象,这个对象有多个字段,在插入这些数据到索引的同时,Elastic search还为这些字段建立索引——倒排索引,因为Elastic search最核心功能是搜索。
那么,倒排索引是个什么样子呢?

首先,来搞清楚几个概念,为此,举个例子:
假设有个user索引,它有四个字段:分别是name,gender,age,address。画出来的话,大概是下面这个样子,跟关系型数据库一样

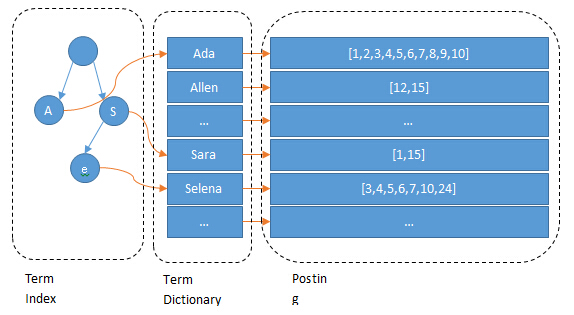
Term(单词):一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term(直译为:单词)
Term Dictionary(单词字典):顾名思义,它里面维护的是Term,可以理解为Term的集合
Term Index(单词索引):为了更快的找到某个单词,我们为单词建立索引
Posting List(倒排列表):倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。(PS:实际的倒排列表中并不只是存了文档ID这么简单,还有一些其它的信息,比如:词频(Term出现的次数)、偏移量(offset)等,可以想象成是Python中的元组,或者Java中的对象)
(PS:如果类比现代汉语词典的话,那么Term就相当于词语,Term Dictionary相当于汉语词典本身,Term Index相当于词典的目录索引)
我们知道,每个文档都有一个ID,如果插入的时候没有指定的话,Elasticsearch会自动生成一个,因此ID字段就不多说了
上面的例子,Elasticsearch建立的索引大致如下:
name字段:

age字段:

gender字段:

address字段:

Elasticsearch分别为每个字段都建立了一个倒排索引。比如,在上面“张三”、“北京市”、22 这些都是Term,而[1,3]就是Posting list。Posting list就是一个数组,存储了所有符合某个Term的文档ID。
只要知道文档ID,就能快速找到文档。可是,要怎样通过我们给定的关键词快速找到这个Term呢?
当然是建索引了,为Terms建立索引,最好的就是B-Tree索引(PS:MySQL就是B树索引最好的例子)。
首先,让我们来回忆一下MyISAM存储引擎中的索引是什么样的:
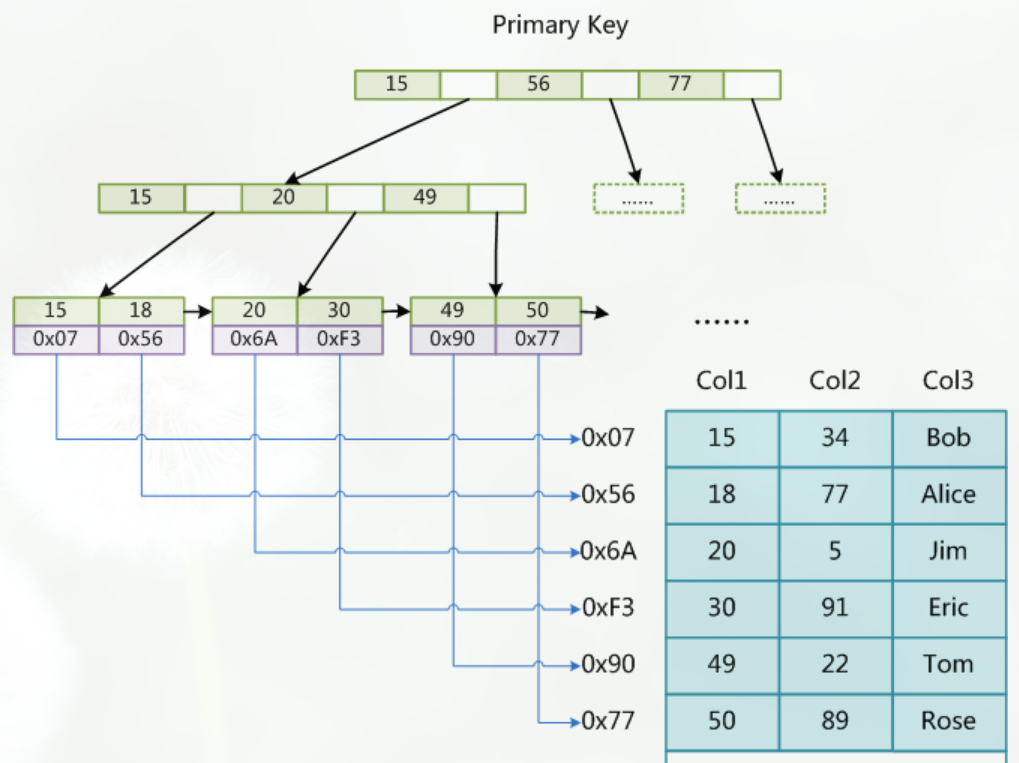
我们查找Term的过程跟在MyISAM中记录ID的过程大致是一样的
MyISAM中,索引和数据是分开,通过索引可以找到记录的地址,进而可以找到这条记录
在倒排索引中,通过Term索引可以找到Term在Term Dictionary中的位置,进而找到Posting List,有了倒排列表就可以根据ID找到文档了
(PS:可以这样理解,类比MyISAM的话,Term Index相当于索引文件,Term Dictionary相当于数据文件)
(PS:其实,前面我们分了三步,我们可以把Term Index和Term Dictionary看成一步,就是找Term。因此,可以这样理解倒排索引:通过单词找到对应的倒排列表,根据倒排列表中的倒排项进而可以找到文档记录)
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
为了更进一步理解,下面从网上摘了两张图来具现化这一过程:
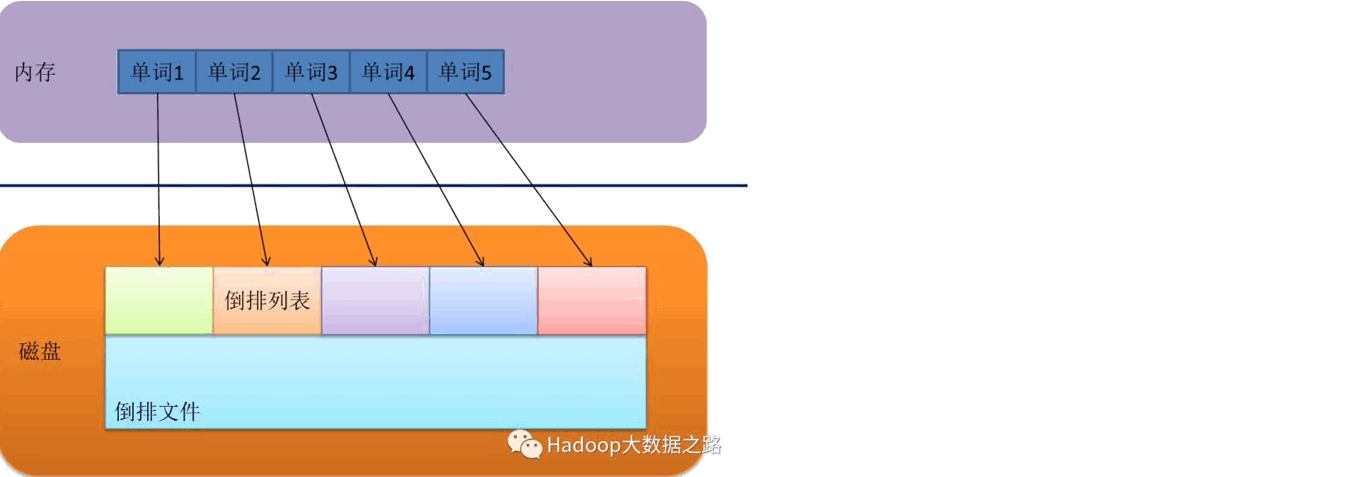
关于倒排索引结构就讲到这里,至于更多细节,比如:压缩,存储那些以后再说
三、商城业务
3.1 索引映射
1. product-es模型分析
分析sku在es中如何存储
分析:商品上架在es中是存sku还是spu?
方案1:
{
skuId:1
spuId:11
skyTitile:华为xx
price:999
saleCount:99
attr:[
{尺寸:5},
{CPU:高通945},
{分辨率:全高清}
]
缺点:如果每个sku都存储规格参数(如尺寸),会有冗余存储,因为每个spu对应的sku的规格参数都一样
方案2:
sku索引
{
spuId:1
skuId:11
}
attr索引
{
skuId:11
attr:[
{尺寸:5},
{CPU:高通945},
{分辨率:全高清}
]
}
先找到4000个符合要求的spu,再根据4000个spu查询对应的属性,封装了4000个id,long 8B*4000=32000B=32KB
1K个人检索,就是32MB
结论:如果将规格参数单独建立索引,会出现检索时出现大量数据传输的问题,会引起网络延迟
因此选用方案1,以空间换时间
2. 建立product索引
最终选用的数据模型:
- “type”: “keyword” # 保持数据精度问题,可以检索,但不分词
- “analyzer”: “ik_smart” # 中文分词器
- “index”: false # 不可被检索,不生成index
- “doc_values”: false # 默认为true,不可被聚合,es就不会维护一些聚合的信息
建立kibanan映射索引:
PUT product
{
"mappings":{
"properties": {
"skuId":{ "type": "long" },
"spuId":{ "type": "keyword" }, # 不可分词
"skuTitle": {
"type": "text",
"analyzer": "ik_smart" # 中文分词器
},
"skuPrice": { "type": "keyword" }, # 保证精度问题
"skuImg" : { "type": "keyword" }, # 视频中有false
"saleCount":{ "type":"long" },
"hasStock": { "type": "boolean" },
"hotScore": { "type": "long" },
"brandId": { "type": "long" },
"catalogId": { "type": "long" },
"brandName": {"type": "keyword"}, # 视频中有false
"brandImg":{
"type": "keyword",
"index": false, # 不可被检索,不生成index,只用做页面使用
"doc_values": false # 不可被聚合,默认为true
},
"catalogName": {"type": "keyword" }, # 视频里有false
"attrs": {
"type": "nested",
"properties": {
"attrId": {"type": "long" },
"attrName": {
"type": "keyword",
"index": false, # 不可被检索,不生成索引
"doc_values": false # 不可被聚合
},
"attrValue": {"type": "keyword" }
}
}
}
}
}
3. nested嵌入式对象
属性是"type": “nested”,因为是内部的属性进行检索
数组类型的对象会被扁平化处理(对象的每个属性会分别存储到一起)
user.name=["aaa","bbb"]
user.addr=["ccc","ddd"]
这种存储方式,可能会发生如下错误:
错误检索到{aaa,ddd},这个组合是不存在的
数组的扁平化处理会使检索能检索到本身不存在的,为了解决这个问题,就采用了嵌入式属性,数组里是对象时用嵌入式属性(不是对象无需用嵌入式属性)
ES对数组的扁平化处理:
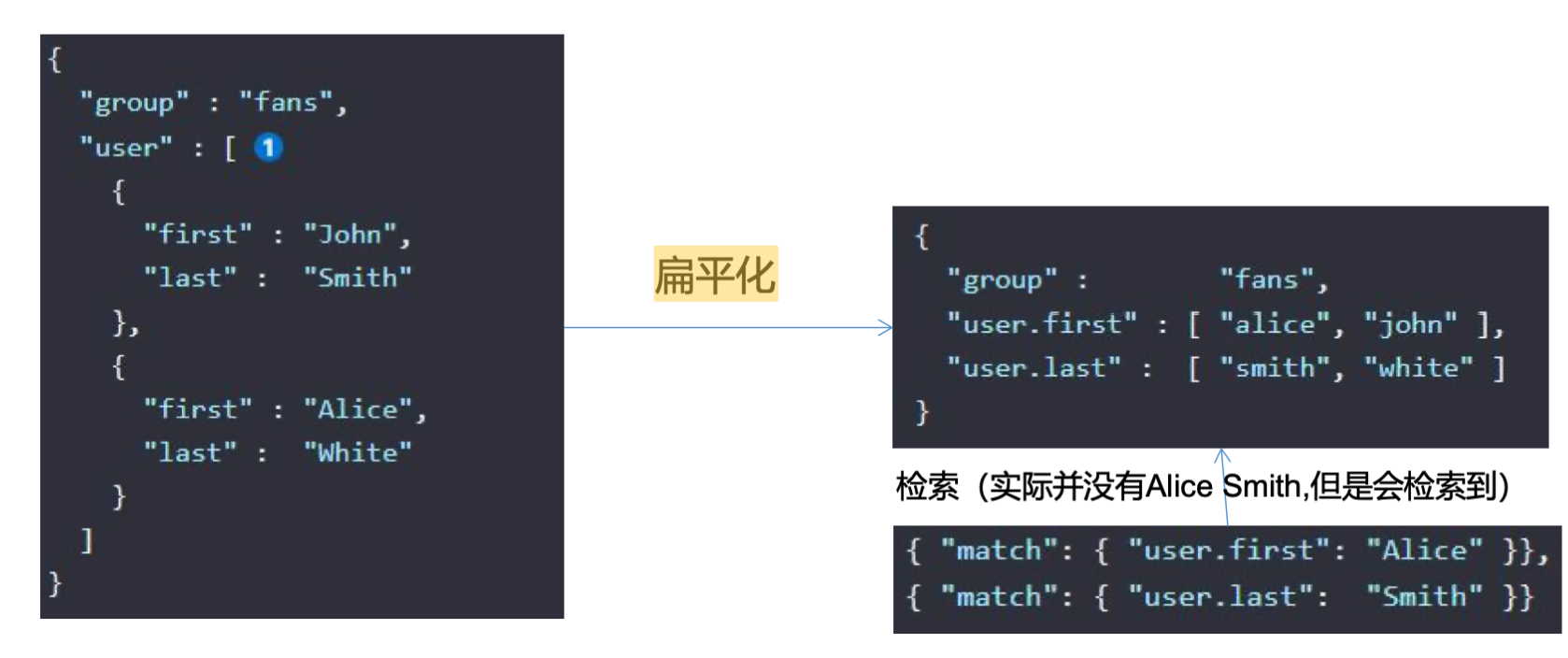
nested阅读:https://blog.csdn.net/weixin_40341116/article/details/80778599
使用聚合:https://blog.csdn.net/kabike/article/details/101460578
3.2 商品上架
1. 映射实体类
商品上架需要在es中保存spu信息并更新spu的状态信息,由于SpuInfoEntity与索引的数据模型并不对应,所以我们要建立专门的vo进行数据传输
@Data
public class SkuEsModel { //common中
private Long skuId;
private Long spuId;
private String skuTitle;
private BigDecimal skuPrice;
private String skuImg;
private Long saleCount;
private boolean hasStock;
private Long hotScore;
private Long brandId;
private Long catalogId;
private String brandName;
private String brandImg;
private String catalogName;
private List<Attr> attrs;
@Data
public static class Attr{
private Long attrId;
private String attrName;
private String attrValue;
}
}
2. 封装商品List集合
具体实现:gitee
@Transactional
@Override
public void saveSpuInfo(SpuSaveVo vo) {
//1、保存spu基本信息:pms_spu_info
SpuInfoEntity spuInfoEntity = new SpuInfoEntity();
BeanUtils.copyProperties(vo,spuInfoEntity); //TODO 商品权重weight的保存好像有点问题
spuInfoEntity.setCreateTime(new Date());
spuInfoEntity.setUpdateTime(new Date());
this.saveBaseSpuInfo(spuInfoEntity);
//2、保存spu的描述图片:pms_spu_info_desc
List<String> decript = vo.getDecript();
SpuInfoDescEntity descEntity = new SpuInfoDescEntity();
descEntity.setSpuId(spuInfoEntity.getId());
descEntity.setDecript(String.join(",",decript));
spuInfoDescService.saveSpuInfoDesc(descEntity);
//3、保存spu的图片集:pms_spu_images
List<String> images = vo.getImages();
spuImagesService.saveImages(spuInfoEntity.getId(),images); ////
//4、保存spu的规格参数:pms_product_attr_value
List<BaseAttrs> baseAttrs = vo.getBaseAttrs();
List<ProductAttrValueEntity> collect = baseAttrs.stream().map(attr -> {
ProductAttrValueEntity valueEntity = new ProductAttrValueEntity();
valueEntity.setAttrId(attr.getAttrId());
//查询attr属性名
AttrEntity byId = attrService.getById(attr.getAttrId());
valueEntity.setAttrName(byId.getAttrName());
valueEntity.setAttrValue(attr.getAttrValues());
valueEntity.setQuickShow(attr.getShowDesc());
valueEntity.setSpuId(spuInfoEntity.getId());
return valueEntity;
}).collect(Collectors.toList());
productAttrValueService.saveProductAttr(collect);
//5、保存spu的积分信息:gulimall_sms--->sms_spu_bounds
Bounds bounds = vo.getBounds();
SpuBoundTo spuBoundTo = new SpuBoundTo();
BeanUtils.copyProperties(bounds,spuBoundTo);
spuBoundTo.setSpuId(spuInfoEntity.getId());
R r = couponFeignService.saveSpuBounds(spuBoundTo);
if (r.getCode() != 0) {
log.error("远程保存spu积分信息失败");
}
//5、保存当前spu对应的所有sku信息:pms_sku_info 👇👇
List<Skus> skus = vo.getSkus();
if(skus!=null && skus.size()>0){
skus.forEach(item->{
//5、1)、保存sku的基本信息:pms_sku_info
String defaultImg = "";
for (Images image : item.getImages()) {
if(image.getDefaultImg() == 1){ //判断是不是设置了默认图片
defaultImg = image.getImgUrl();
}
}
SkuInfoEntity skuInfoEntity = new SkuInfoEntity();
BeanUtils.copyProperties(item,skuInfoEntity);
skuInfoEntity.setBrandId(spuInfoEntity.getBrandId());
skuInfoEntity.setCatalogId(spuInfoEntity.getCatalogId());
skuInfoEntity.setSaleCount(0L);
skuInfoEntity.setSpuId(spuInfoEntity.getId());
skuInfoEntity.setSkuDefaultImg(defaultImg);
skuInfoService.saveSkuInfo(skuInfoEntity);
//5、2)、保存sku的图片信息:pms_sku_images
Long skuId = skuInfoEntity.getSkuId();
List<SkuImagesEntity> imagesEntities = item.getImages().stream().map(img -> {
SkuImagesEntity skuImagesEntity = new SkuImagesEntity();
skuImagesEntity.setSkuId(skuId);
skuImagesEntity.setImgUrl(img.getImgUrl());
skuImagesEntity.setDefaultImg(img.getDefaultImg());
return skuImagesEntity;
}).filter(entity -> {
//返回true就是需要,false就是剔除
return !StringUtils.isEmpty(entity.getImgUrl());
}).collect(Collectors.toList());
skuImagesService.saveBatch(imagesEntities);
//5、3)、保存sku的销售属性:pms_sku_sale_attr_value
List<Attr> attr = item.getAttr();
List<SkuSaleAttrValueEntity> skuSaleAttrValueEntities = attr.stream().map(a -> {
SkuSaleAttrValueEntity skuSaleAttrValueEntity = new SkuSaleAttrValueEntity();
BeanUtils.copyProperties(a, skuSaleAttrValueEntity);
skuSaleAttrValueEntity.setSkuId(skuId);
return skuSaleAttrValueEntity;
}).collect(Collectors.toList());
skuSaleAttrValueService.saveBatch(skuSaleAttrValueEntities);
//5、4)、保存sku的优惠、满减等信息:gulimall_sms--->sms_sku_ladder、sms_sku_full_reduction、sms_member_price
SkuReductionTo skuReductionTo = new SkuReductionTo();
BeanUtils.copyProperties(item,skuReductionTo);
skuReductionTo.setSkuId(skuId);
List<MemberPrice> memberPrice = item.getMemberPrice();
List<MemberPriceTo> memberPriceToList = memberPrice.stream().map(member -> {
MemberPriceTo memberPriceTo = new MemberPriceTo();
memberPriceTo.setPrice(member.getPrice());
memberPriceTo.setId(member.getId());
memberPriceTo.setName(member.getName());
return memberPriceTo;
}).collect(Collectors.toList());
skuReductionTo.setMemberPrice(memberPriceToList);
if (skuReductionTo.getFullCount() > 0 || skuReductionTo.getFullPrice().compareTo(BigDecimal.ZERO) == 1) {
R r1 = couponFeignService.saveSkuReduction(skuReductionTo);
if (r1.getCode() != 0) {
log.error("远程保存sku积分信息失败");
}
}
});
}
}
3. 调用search服务保存到ES
官网文档:https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/8.3/indexing-bulk.html
@SneakyThrows
@Override
public boolean productStatusUp(List<SkuEsModel> skuEsModels){
//构造批量保存对象
BulkRequest.Builder br = new BulkRequest.Builder();
for (SkuEsModel skuEsModel : skuEsModels) {
br.operations(op->op
.index(idx->idx
.index(EsConstant.PRODUCT_INDEX) //哪个索引
.id(skuEsModel.getSkuId().toString()) //id
.document(skuEsModel) //具体文档
)
);
}
//执行批量保存对象
BulkResponse result = elasticsearchClient.bulk(br.build());
//分析响应结果
boolean b = false;
List<String> collect = null;
if (result.errors()) {
log.info("商品上架出现了问题");
b = true;
for (BulkResponseItem item : result.items()) {
if (item.error()!=null) {
collect.add(item.error().reason());
}
}
log.info("错误信息:{}",collect);
}
return b;
}
3.2 商品检索
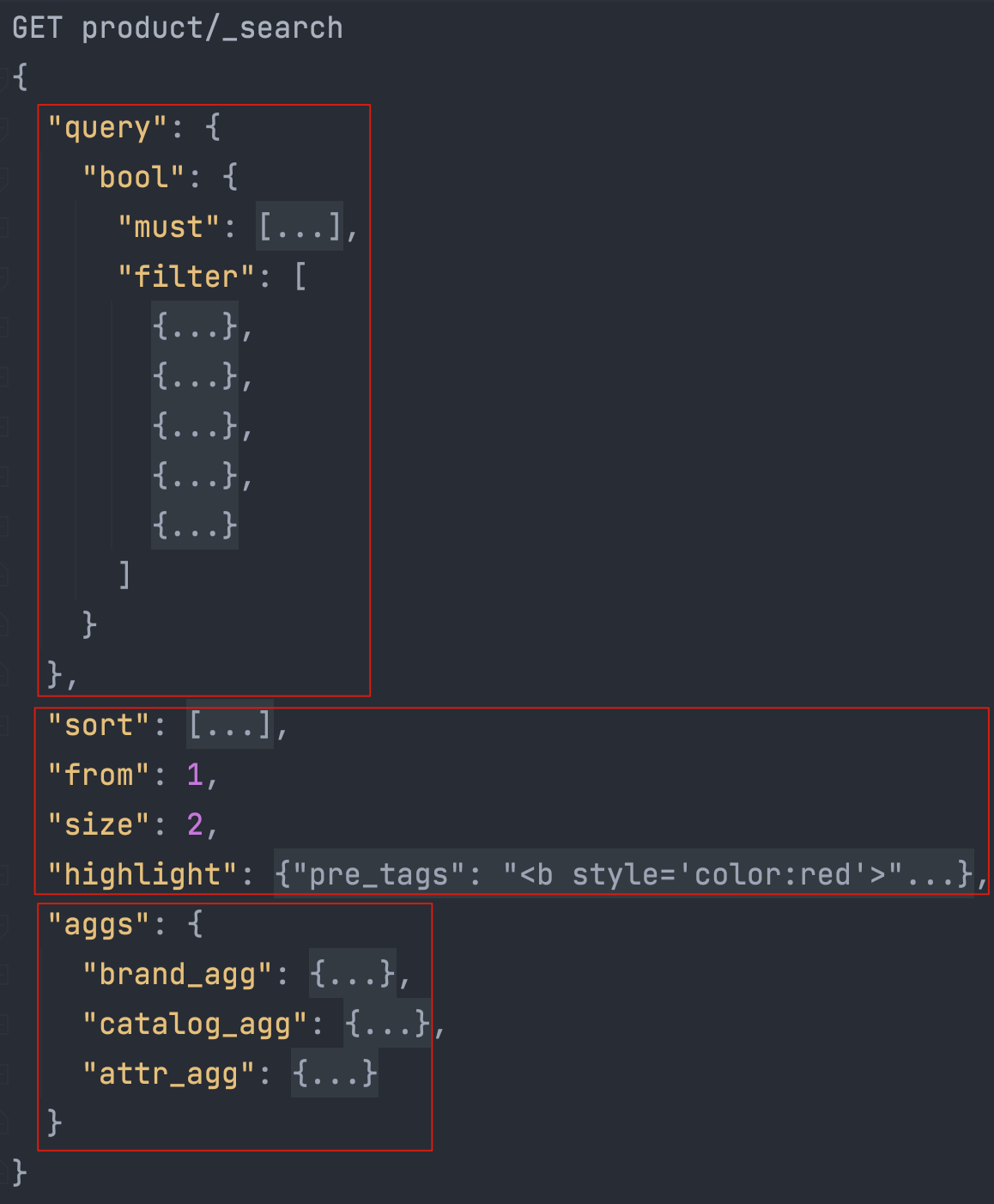
1. 控制台检索示例
//# 模糊匹配,过滤(分类、品牌、属性、库存、价格区间),排序,分页,高亮,聚合分析
GET gulimall_product/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"skuTitle": "苹果小米"
}
}
],
"filter": [
{
"term": {
"catalogId": "225"
}
},
{
"terms": {
"brandId": [
"18",
"19"
]
}
},
{
"nested": {
"path": "attrs",
"query": {
"bool": {
"must": [
{
"term": {
"attrs.attrId": {
"value": "11"
}
}
},
{
"terms": {
"attrs.attrValue": [
"不可拆卸",
"亮度",
"徕卡摄影",
"超广角"
]
}
}
]
}
}
}
},
{
"term": {
"hasStock": "false"
}
},
{
"range": {
"skuPrice": {
"gte": 5000,
"lte": 7000
}
}
}
]
}
},
"sort": [
{
"skuPrice": {
"order": "desc"
}
}
],
"from": 1,
"size": 2,
"highlight": {
"fields": {
"skuTitle": {
}
},
"pre_tags": "<b style='color:red'>",
"post_tags": "</b>"
},
"aggs": {
"brand_agg": {
"terms": {
"field": "brandId",
"size": 10
},
"aggs": {
"brand_name_agg": {
"terms": {
"field": "brandName",
"size": 10
}
},
"brand_img_agg": {
"terms": {
"field": "brandImg",
"size": 10
}
}
}
},
"catalog_agg": {
"terms": {
"field": "catalogId",
"size": 10
},
"aggs": {
"catalog_name_agg": {
"terms": {
"field": "catalogName",
"size": 10
}
}
}
},
"attr_agg": {
"nested": {
"path": "attrs"
},
"aggs": {
"attr_id_agg": {
"terms": {
"field": "attrs.attrId",
"size": 10
},
"aggs": {
"attr_name_agg": {
"terms": {
"field": "attrs.attrName",
"size": 10
},
"aggs": {
"attr_value_agg": {
"terms": {
"field": "attrs.attrValue",
"size": 10
}
}
}
}
}
}
}
}
}
}
折叠如下:
2. 检索参数
检索参数封装
/**
* 封装页面所有可能传递的页面
*/
@Data
public class SearchParamVo {
//全文检索
private String keyword;
private Long catalog3Id;
/**
*排序条件:
*销量:saleCount_asc/desc
*价格: skuPrice_asc/desc
*热度评分: hotScore_asc/desc
*/
private String sort;
/**
* 过滤:
*仅显示有货:hasStock=0/1
*价格区间:skuPrice=1_500/_500/500_
* 品牌(多选)
* 商品属性(多选)
*/
private Integer hasStock;
private String skuPrice;
private Integer skuPrice1;
private Integer skuPrice2;
private List<Long> brandId;
private List<String> attrs;
//分页
private Integer pageNum = 1;
private String _queryString;//原生查询条件
}
3. 检索业务流程
具体实现:gitee
检索流程
@Override
public SearchResults search(SearchParamVo paramVo) {
//检索请求返回对象
SearchResponse<SkuEsModel> result = null;
//构造检索请求,具体构造在buildSearchRequest方法中
Function<SearchRequest.Builder, ObjectBuilder<SearchRequest>> request = builder -> buildSearchRequest(paramVo);
try {
//执行检索请求
result = client.search(request,SkuEsModel.class);
} catch (Exception e) {
e.printStackTrace();
}
//封装检索返回数据,实现在buildSearchResult方法中
SearchResults searchResult = null;
if (result!=null) {
searchResult = buildSearchResult(result, paramVo);
}
return searchResult;
}
4. 构造检索请求
private SearchRequest.Builder buildSearchRequest(SearchParamVo param) {
SearchRequest.Builder builder = new SearchRequest.Builder();
//================================================================================
/**
* 首先构造查询query 模糊匹配,过滤(按照属性,分类,品牌,价格区间,库存)
* BoolQuery.Builder boolBuilder = QueryBuilders.bool();
*/
BoolQuery.Builder boolBuilder = QueryBuilders.bool();
// 检索关键字
if (StringUtils.isNotBlank(param.getKeyword())) {
boolBuilder.must(_0 -> _0
.match(_1 -> _1
.field("skuTitle")
.query(FieldValue.of(param.getKeyword()))
));
}
// 分类
if (param.getCatalog3Id() != null) {
boolBuilder.filter(_0 -> _0
.term(_1 -> _1
.field("catalogId")
.value(FieldValue.of(param.getCatalog3Id()))));
}
// 品牌
if (CollectionUtils.isNotEmpty(param.getBrandId())) {
List<FieldValue> collect = param.getBrandId().stream().map(FieldValue::of).collect(Collectors.toList());
boolBuilder.filter(_0 -> _0
.terms(_1 -> _1.field("brandId")
.terms(_2 -> _2.value(collect))));
}
// 库存
if (param.getHasStock() != null) {
boolBuilder.filter(_0 -> _0
.term(_1 -> _1
.field("hasStock")
.value(FieldValue.of(param.getHasStock() == 1))));
}
// 价格区间
if (StringUtils.isNotEmpty(param.getSkuPrice())) {
// 1_500/_500/500_
String[] s = param.getSkuPrice().split("_");
RangeQuery.Builder builder2 = new RangeQuery.Builder().field("skuPrice");
if (s.length == 2) {
// 区间
builder2.gte(JsonData.of(new BigDecimal("".equals(s[0]) ? "0" : s[0])));
if (!"".equals(s[1])) builder2.lte(JsonData.of(new BigDecimal(s[1])));
} else if (param.getSkuPrice().startsWith("_")) {
builder2.lte(JsonData.of(s[0]));
// _500
} else if (param.getSkuPrice().endsWith("_")) {
builder2.gte(JsonData.of(s[0]));
// 500_
}
boolBuilder.filter(_0 -> _0.range(builder2.build()));
}
// 属性 需要扁平化处理
if (CollectionUtils.isNotEmpty(param.getAttrs())) {
// attrs=1_5寸:8寸&attrs=2_16G:8G
for (String attrStr : param.getAttrs()) {
BoolQuery.Builder boolQuery = QueryBuilders.bool();
String[] s = attrStr.split("_");
String attrId = s[0];
String[] attrValues = s[1].split(":");
boolQuery.must(_0 -> _0
.term(_1 -> _1
.field("attrs.attrId")
.value(FieldValue.of(attrId))));
boolQuery.must(_0 -> _0
.terms(_1 -> _1
.field("attrs.attrValue")
.terms(_2 -> _2.value(
Arrays.stream(attrValues).map(
FieldValue::of
).collect(Collectors.toList())
))));
boolBuilder.filter(_0 -> _0
.nested(QueryBuilders.nested()
.path("attrs")
.query(a -> a.bool(boolQuery.build())).build()));
}
}
builder.query(builderFinal->builderFinal.bool(boolBuilder.build()));
//================================================================================
builder.index(EsConstant.PRODUCT_INDEX); //指定索引
//================================================================================
/**
* 排序、分页、高亮
*/
if (StringUtils.isNotEmpty(param.getSort())) {
//sort = skuPrice_asc/desc
String sort = param.getSort();
String[] s = sort.split("_");
builder.sort(_0->_0
.field(_1->_1
.field(s[0])
.order(s[1].equalsIgnoreCase("asc")?SortOrder.Asc:SortOrder.Desc)));
}
builder.from((param.getPageNum() - 1) * EsConstant.PRODUCT_PAGESIZE);
builder.size(EsConstant.PRODUCT_PAGESIZE);
if (!StringUtils.isEmpty(param.getKeyword())) {
builder.highlight(_0->_0
.fields("skuTitle",_1->_1
.preTags("<b style='color:red'>")
.postTags("</b>")));
}
//================================================================================
/**
* 聚合:品牌、分类、属性
*/
Map<String , Aggregation> map = new HashMap<>();
map.put("brand_agg",Aggregation.of(_0->_0
.terms(_1->_1.field("brandId").size(10))
.aggregations("brand_name_agg",_2->_2
.terms(_3->_3.field("brandName").size(10)))
.aggregations("brand_img_agg",_4->_4
.terms(_5->_5.field("brandImg").size(10)))));
map.put("catalog_agg",Aggregation.of(_0->_0
.terms(_1->_1.field("catalogId").size(10))
.aggregations("catalog_name_agg",_2->_2
.terms(_3->_3.field("catalogName").size(10)))));
map.put("attr_agg",Aggregation.of(_0->_0
.nested(_1->_1.path("attrs"))
.aggregations("attr_id_agg",_2->_2
.terms(_3->_3.field("attrs.attrId").size(10))
.aggregations("attr_name_agg",_4->_4
.terms(_5->_5.field("attrs.attrName").size(10)))
.aggregations("attr_value_agg",_6->_6
.terms(_7->_7.field("attrs.attrValue").size(10))))));
builder.aggregations(map);
//================================================================================
return builder;
}
5. 返回值参数
JavaBean对象
@Data
public class SearchResults {
private List<SkuEsModel> products;
/**
* 分页信息
*/
private Integer pageNum;//当前页
private Long total;//总记录数
private Long totalPage;//总页码
private List<Integer> pageNavs;
private List<BrandVo> brands;//品牌信息
private List<AttrVo> attrs;//属性信息
private List<CatalogVo> catalogs;//分类信息
private List<NavVo> navs = new ArrayList<>();
private List<Long> attrIds = new ArrayList<>();
/**
*面包屑导航静态内部类
*/
@Data
public static class NavVo{
private String navName;
private String navValue;
private String link;
}
/**
* 品牌内部类
*/
@Data
public static class BrandVo{
private Long brandId;
private String brandName;
private String brandImg;
}
/**
* 属性内部类
*/
@Data
public static class AttrVo{
private Long attrId;
private String attrName;
private List<String> attrValue;
}
/**
* 分类内部类
*/
@Data
public static class CatalogVo {
private Long catalogId;
private String catalogName;
}
}
6. 封装返回值
private SearchResults buildSearchResult(SearchResponse<SkuEsModel> result,SearchParamVo param){
System.err.println(result);
SearchResults searchResults = new SearchResults();
HitsMetadata<SkuEsModel> hits = result.hits();
Map<String, Aggregate> aggregations = result.aggregations();
// 1.返回所有查询到的商品
List<Hit<SkuEsModel>> hits1 = hits.hits();
if (CollectionUtils.isNotEmpty(hits1)) {
List<SkuEsModel> skuEsModels = new ArrayList<>();
for (Hit<SkuEsModel> hit : hits1) {
SkuEsModel source = hit.source();
//替换高亮字段,关键字查询高亮才能生效
if (StringUtils.isNotEmpty(param.getKeyword())) {
if (source!=null) {
String skuTitle = hit.highlight().get("skuTitle").toString();
source.setSkuTitle(skuTitle);
}
}
skuEsModels.add(source);
}
searchResults.setProducts(skuEsModels);
}
//=============================================================================
// 2. 当前商品所涉及到的所有属性信息--聚合信息
Aggregate attr_agg = aggregations.get("attr_agg");
if (attr_agg!=null) {
List<LongTermsBucket> attr_id_agg = attr_agg.nested().aggregations().get("attr_id_agg").lterms().buckets().array();
List<SearchResults.AttrVo> attrVos = new ArrayList<>();
if (CollectionUtils.isNotEmpty(attr_id_agg)) {
for (LongTermsBucket longTermsBucket : attr_id_agg) {
SearchResults.AttrVo attrVo = new SearchResults.AttrVo();
attrVo.setAttrId(longTermsBucket.key());
attrVo.setAttrName(longTermsBucket.aggregations().get("attr_name_agg").sterms().buckets().array().get(0).key());
//属性value聚合值
List<StringTermsBucket> attr_value_agg = longTermsBucket.aggregations().get("attr_value_agg").sterms().buckets().array();
if (attr_value_agg!=null) {
ArrayList<String> strings = new ArrayList<>();
for (StringTermsBucket stringTermsBucket : attr_value_agg) {
strings.add(stringTermsBucket.key());
}
attrVo.setAttrValue(strings);
}
attrVos.add(attrVo);
}
}
searchResults.setAttrs(attrVos);
}
// 3.当前所有商品所涉及到的的所有品牌信息--聚合信息
Aggregate brand_agg = aggregations.get("brand_agg");
if (brand_agg != null) {
List<SearchResults.BrandVo> brandVos = new ArrayList<>();
List<LongTermsBucket> idAgg = brand_agg.lterms().buckets().array();
if (CollectionUtils.isNotEmpty(idAgg)) {
for (LongTermsBucket longTermsBucket : idAgg) {
SearchResults.BrandVo brandVo = new SearchResults.BrandVo();
// brand_agg 的key即为 brandId
brandVo.setBrandId(longTermsBucket.key());
// 从子聚合中找出 品牌名 一个品牌id对应唯一一个品牌名
brandVo.setBrandName(longTermsBucket.aggregations().get("brand_name_agg").sterms().buckets().array().get(0).key());
// 从子聚合中找出 图片 一个品牌id对应唯一一个图片
brandVo.setBrandImg(longTermsBucket.aggregations().get("brand_img_agg").sterms().buckets().array().get(0).key());
brandVos.add(brandVo);
}
}
searchResults.setBrands(brandVos);
}
// 4.当前所有商品所涉及到的的所有分类信息--聚合信息
Aggregate catalog_agg = aggregations.get("catalog_agg");
if (catalog_agg != null) {
List<SearchResults.CatalogVo> catalogVos = new ArrayList<>();
List<LongTermsBucket> idAgg = catalog_agg.lterms().buckets().array();
if (CollectionUtils.isNotEmpty(idAgg)) {
for (LongTermsBucket longTermsBucket : idAgg) {
SearchResults.CatalogVo catalogVo = new SearchResults.CatalogVo();
// 设置分类id
catalogVo.setCatalogId(longTermsBucket.key());
// 从子聚合中找出 分类名
// 注意:一个分类id一定对应唯一的分类名,
// 因此只需要对 id 的聚合进行遍历
catalogVo.setCatalogName(longTermsBucket.aggregations().get("catalog_name_agg").sterms().buckets().array().get(0).key());
catalogVos.add(catalogVo);
}
}
searchResults.setCatalogs(catalogVos);
}
// 5.页码信息11/3
long total = hits.total()!=null?hits.total().value():0;
long totalPages = (total % EsConstant.PRODUCT_PAGESIZE == 0) ? total / EsConstant.PRODUCT_PAGESIZE : (total / EsConstant.PRODUCT_PAGESIZE) + 1;
searchResults.setPageNum(param.getPageNum()); //当前页
searchResults.setTotal(total); //总记录数
searchResults.setTotalPage(totalPages); //总页码
List<Integer> pageNavs = new ArrayList<>();
for (int i = 1; i < totalPages; i++) {
pageNavs.add(i);
}
searchResults.setPageNavs(pageNavs);
//6.构建面包屑导航
//属性面包屑导航
if (param.getAttrs() != null && param.getAttrs().size() > 0) {
List<SearchResults.NavVo> collect = param.getAttrs().stream().map(attr -> {
SearchResults.NavVo navVo = new SearchResults.NavVo();
//分析每个attr的参数值
String[] s = attr.split("_");
navVo.setNavValue(s[1]);
R r = productFeignService.attrInfo(Long.parseLong(s[0]));
searchResults.getAttrIds().add(Long.parseLong(s[0]));
if (r.getCode() == 0) {
Object attr1 = r.get("attr");
String s1 = JSON.toJSONString(attr1);
AttrResponseVo attrs = JSON.parseObject(s1, new TypeReference<AttrResponseVo>() {});
navVo.setNavName(attrs.getAttrName());
} else {
navVo.setNavName(s[0]);
}
String replace = replaceQueryString(param, attr, "attrs");
navVo.setLink("http://search.gulimall.com/list.html?" + replace);
return navVo;
}).collect(Collectors.toList());
searchResults.setNavs(collect);
}
//品牌、分类面包屑导航
if (param.getBrandId() != null && param.getBrandId().size() > 0) {
List<SearchResults.NavVo> navs = searchResults.getNavs();
SearchResults.NavVo navVo = new SearchResults.NavVo();
navVo.setNavName("品牌");
//远程查询所有品牌
R r = productFeignService.brandsInfo(param.getBrandId());
if (r.getCode() == 0) {
Object brands1 = r.get("brands");
String s2 = JSON.toJSONString(brands1);
List<BrandVo> brands = JSON.parseObject(s2, new TypeReference<List<BrandVo>>() {});
StringBuffer buffer = new StringBuffer();
String replace = "";
for (BrandVo brandVo : brands){
buffer.append(brandVo.getName()+";");
replace = replaceQueryString(param,brandVo.getBrandId()+"","brandId");
}
navVo.setNavValue(buffer.toString());
navVo.setLink("http://search.gulimall.com/list.html?" + replace);
}
navs.add(navVo);
}
return searchResults;
}
//取消了面包屑之后,跳转的位置(将请求地址的url替换,置空)
private String replaceQueryString(SearchParamVo paramVo, String value, String key) {
String encode = null;
try {
//编码
encode = URLEncoder.encode(value, "UTF-8");
encode = encode.replace("+", "%20");//对空格特殊处理(将空格变为%20)
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return paramVo.get_queryString().replace("&" + key + "=" + encode, "");
}
四、集群搭建
后续补充。。。
五、其他javaClient操作
官网文档:https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/8.3/introduction.html
5.1 安装ik分词器
所有的语言分词,默认使用的都是Standard Analyzer,但是这些分词器针对于中文的分词,并不友好。为此需要安装中文的分词器。
可以把他连接到mysql,让他们从mysql拉取
可以随便找一篇参考https://blog.csdn.net/wuzhiwei549/article/details/80451302
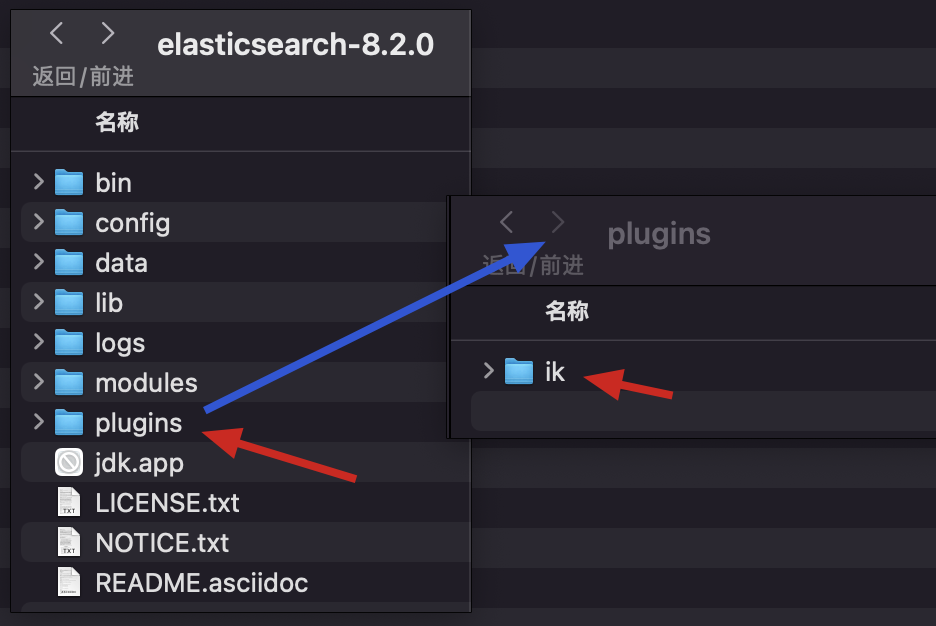
1.安装ik分词器
下载与ES版本相同的压缩包:GitHub->Releases
解压放入如下位置即可生效:
2. 测试分词器
使用默认分词器
GET _analyze
{
"text":"我是中国人"
}
观察执行结果:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "中",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "国",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "人",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
使用ik分词器(最粗粒度分词):
GET _analyze
{
"analyzer": "ik_smart",
"text":"我是中国人"
}
输出结果:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
使用ik分词器(最细粒度分词):
GET _analyze
{
"analyzer": "ik_max_word",
"text":"我是中国人"
}
输出结果:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
指定分词器测试
localhost:9200/_analyze?analyzer=standard&pretty=true&text=美好
{
"tokens": [
{
"token": "美",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "好",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
}
]
}
3. 自定义本地词库
- 修改
elasticsearch/plugins/ik/config中的IKAnalyzer.cfg.xml,添加konan.dic
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">konan.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict"></entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 在
IKAnalyzer.cfg.xml同级目录建立konan.dic文件
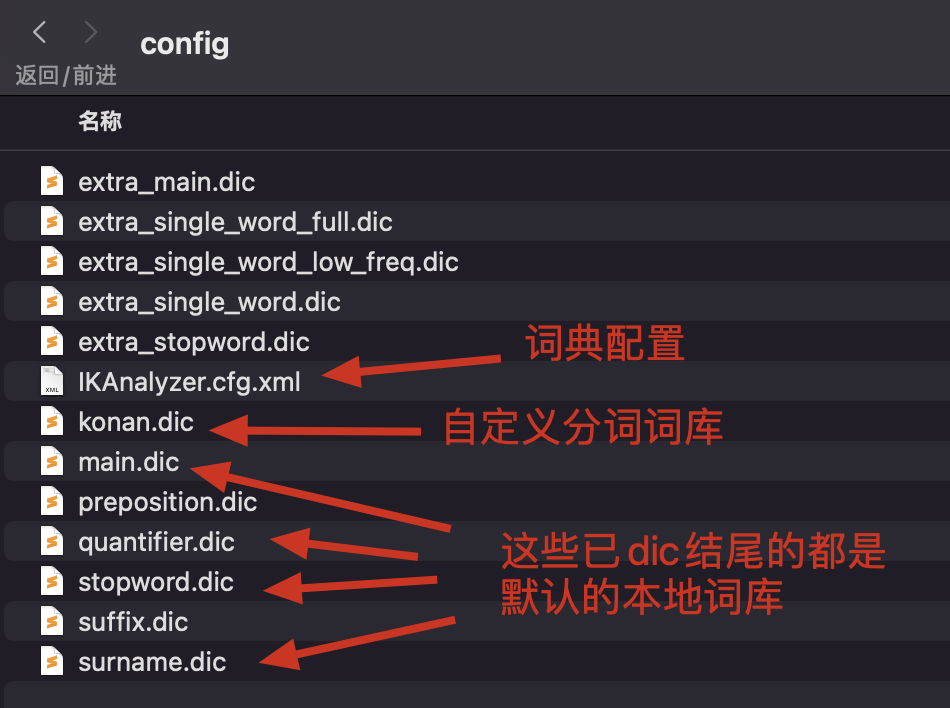
- 写入如下内容(换行分隔):

修改完成后,需要重启elasticsearch容器 docker restart elasticsearch
POST my_index/_update_by_query?conflicts=proceed
4. 自定义远程词库
-
在nginx的
html文件夹下创建ik.dic或ik.txt文件-
此时访问http://127.0.0.1/ik.dic应可以访问到词典
-
因为nginx中的默认配置,访问
/即直接访问到html路径下的文件location / { root /usr/share/nginx/html; index index.html index.htm; }
-
-
修改
elasticsearch/plugins/ik/config中的IKAnalyzer.cfg.xml,添加相应地址
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">konan.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://127.0.0.1/ik.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 重启ES容器即可生效
5.2 固定条件检索
查询name字段包含hello的文档
@Test
void contextLoads() {
SearchResponse<Object> search = null;
try {
search = elasticsearchClient.search(s -> s
.index("bank")
//查询name字段包含hello的document(不使用分词器精确查找)
.query(q -> q
.match(t -> t
.field("name")
.query("hello")
)), Object.class
);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(search);
}
解耦构建–聚合查询–结果分析
@SneakyThrows
@Test
void Search() {
String searchText = "mill";
//构建查询
Query query = MatchQuery.of(m -> m
.field("address")
.query(searchText))._toQuery();
SearchResponse<userTest> search = elasticsearchClient.search(s -> s
.index("bank")
.query(query) //这里直接引用上文封装的结果,比较简洁直观
.aggregations("ageAgg",a->a
.terms(t->t
.field("age")
.size(10))
)
.aggregations("ageAve",a->a
.avg(av->av
.field("age"))
)
.aggregations("balanceAvg",a->a
.avg(av->av
.field("balance"))
), userTest.class);
System.out.println(search);
AvgAggregate ageAve = search.aggregations().get("ageAve").avg();
JSONObject parse = (JSONObject)JSON.parse(String.valueOf(ageAve));
System.out.println("平均年龄:"+parse.get("value"));
AvgAggregate balanceAvg = search.aggregations().get("balanceAvg").avg();
JSONObject parse1 =(JSONObject) JSON.parse(String.valueOf(balanceAvg));
System.out.println("平均工资:"+parse1.get("value"));
List<LongTermsBucket> ageAgg = search.aggregations().get("ageAgg").lterms().buckets().array();
for (LongTermsBucket longTermsBucket : ageAgg) {
System.out.println("年龄:"+longTermsBucket.key()+"数量:"+longTermsBucket.docCount());
}
List<Hit<userTest>> hits = search.hits().hits();
for (Hit<userTest> hit: hits) {
userTest source = hit.source();
System.out.println("内部数据:" + source + " 得分 " + hit.score());
System.out.println(source.getEmail());
}
}
关键字高亮分页查询
@Autowired
private ElasticsearchClient elasticsearchClient;
public List<Map<String,Object>> search(String keyword,Integer pageIndex,Integer pageSize){
if (pageIndex<0){pageIndex=0;}
SearchResponse<Content> search = null;
try {
Integer finalPageIndex = pageIndex;
search = elasticsearchClient.search(s -> s
.index("jd_goods")
//查询name字段包含hello的document(不使用分词器精确查找)
.query(q -> q
.term(t -> t
.field("name")
.value(v -> v.stringValue(keyword))
))
//分页查询,从第0页开始查询n个document //按age降序排序 .sort(f->f.field(o->o.field("age").order(SortOrder.Desc)))
.from(finalPageIndex)
.size(pageSize)
.highlight(h->h.fields("name",f->f.preTags("<span style='color:red'>").postTags("</span>"))),
Content.class
);
} catch (IOException e) {
e.printStackTrace();
}
List<Map<String,Object>> contents = new ArrayList<>();
assert search != null;
for (Hit<Content> hit : search.hits().hits()) {
Content source = hit.source();
//替换掉高亮才能生效
String name = hit.highlight().get("name").toString();
assert source != null;
source.setName(name);
Map<String, Object> map = new HashMap<>();
map.put("name",source.getName());
map.put("img",source.getImg());
map.put("price",source.getPrice());
contents.add(map);
}
return contents;
}
5.3 创建索引
一般在kibana中创建
@Test
void createIndex() throws IOException {
//封装各个字段
Map<String, Property> documentMap = new HashMap<>();
documentMap.put("userName", Property.of(property ->
property.text(TextProperty.of(textProperty ->
textProperty.index(true).analyzer("ik_max_word"))
)
)
);
documentMap.put("age", Property.of(property ->
property.integer(IntegerNumberProperty.of(integerNumberProperty
-> integerNumberProperty.index(true))
)
)
);
//执行索引创建
CreateIndexResponse createIndexResponse = elasticsearchClient.indices().create(createIndexBuilder ->
createIndexBuilder.index("user").mappings(mappings -> mappings.properties(documentMap))
.aliases("User",aliases -> aliases.isWriteIndex(true))
);
Boolean acknowledged = createIndexResponse.acknowledged();
System.out.println("acknowledged = " + acknowledged);
}
5.4 删除索引
@Test
void deleteIndex() throws IOException {
DeleteIndexResponse deleteIndexResponse = elasticsearchClient.indices().delete(index
-> index.index("user")
);
boolean acknowledged = deleteIndexResponse.acknowledged();
System.out.println("acknowledged = " + acknowledged);
}
5.5 查看索引信息
@Test
void getIndex() throws IOException {
GetIndexResponse getIndexResponse = elasticsearchClient.indices().get(getIndex -> getIndex.index("user"));
Map<String, IndexState> result = getIndexResponse.result();
result.forEach((k, v) -> System.out.println("key = " + k + ", value = " + v));
}
5.6 添加或修改单个文档
@Test
void updateDocument() {
GoodSpuElasticsearchModel goodSpuElasticsearchModel = new GoodSpuElasticsearchModel(1L, "千岛", 65, "JavaEE" +
"企业级开发.png" , 1, "新华出版社", 30, "书籍");
try {
UpdateResponse<GoodSpuElasticsearchModel> user =
elasticsearchClient.update(u -> u.index("user").id("1").doc(goodSpuElasticsearchModel),
GoodSpuElasticsearchModel.class);
System.out.println(user);
} catch (IOException e) {
e.printStackTrace();
}
}
5.7 根据id删除单个文档
@Test
void deleteOneDocument() throws IOException {
DeleteResponse deleteResponse = elasticsearchClient.delete(a ->
a.index("good_spu").id("1"));
System.out.println("result = " + deleteResponse.result());
}
5.8 批量保存文档
@Test
void addDocumentList() throws IOException {
List<GoodSpuElasticsearchModel> list = new ArrayList<>();
list.add(new GoodSpuElasticsearchModel(1L, "Java企业及开发", 50, "Java企业及开发.png" , 1, "新华出版社", 30, "书籍"));
list.add(new GoodSpuElasticsearchModel(2L, "Java编程", 55, "Java编程.png" , 1, "新华出版社", 30, "书籍"));
list.add(new GoodSpuElasticsearchModel(3L, "Java入门到精通", 70, "Java入门到精通.png" , 1, "新华出版社", 30, "书籍"));
list.add(new GoodSpuElasticsearchModel(4L, "Hadoop权威指南", 110, "Hadoop权威指南" , 1, "新华出版社", 30, "书籍"));
list.add(new GoodSpuElasticsearchModel(5L, "编译原理", 75, "编译原理" , 1, "新华出版社", 30, "书籍"));
list.add(new GoodSpuElasticsearchModel(6L, "操作原理", 60, "操作原理" , 1, "新华出版社", 30, "书籍"));
List<BulkOperation> bulkOperations = new ArrayList<>();
list.forEach(a ->
bulkOperations.add(BulkOperation.of(b ->
b.index(c -> c.id(String.valueOf(a.getGoodSpuId())).document(a))
))
);
BulkResponse bulkResponse = elasticsearchClient.bulk(x -> x.index("good_spu").operations(bulkOperations));
bulkResponse.items().forEach(i -> System.out.println("i = " + i.result()));
System.out.println("bulkResponse.errors() = " + bulkResponse.errors());
}
5.9 批量删除文档
@Test
void deleteDocumentList() throws IOException {
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
list.add("6");
List<BulkOperation> bulkOperations = new ArrayList<>();
list.forEach(a ->
bulkOperations.add(BulkOperation.of(b ->
b.delete(c -> c.id(a))
))
);
BulkResponse bulkResponse = elasticsearchClient.bulk(a -> a.index("good_spu").operations(bulkOperations));
bulkResponse.items().forEach(a -> System.out.println("result = " + a.result()));
System.out.println("bulkResponse.errors() = " + bulkResponse.errors());
}
评论