
说明:本系列笔记总结自
雷丰阳老师教学项目《谷粒商城》
- 视频地址:直达BiliBili
- 完整项目地址:直达gitee
- 本篇主要对应代码: gitee地址
- 项目资料获取:
- 本地缓存:和微服务同一个进程。缺点:分布式时无法锁住其他服务
- 分布式缓存:缓存中间件,拿到同一把锁
本地缓存-redis
安装docker-redis
product导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置redis主机地址
spring:
redis:
host: 127.0.0.1
port: 6380
自动注入了RedisTemplate
优化菜单获取业务getCatalogJson,将分级防止到redis-list中
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
String catalogJson = ops.get("catalogJson");
if (catalogJson == null) {
Map<String, List<Catalog2Vo>> categoriesDb = getCategoriesDb();
String toJSONString = JSON.toJSONString(categoriesDb);
ops.set("catalogJson",toJSONString);
return categoriesDb;
}
Map<String, List<Catalog2Vo>> listMap = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catalog2Vo>>>() {});
return listMap;
lettuce堆外内存溢出
新版本现已修复
当进行压力测试时后期后出现堆外内存溢出OutOfDirectMemoryError
产生原因:
1)、springboot2.0以后默认使用lettuce作为操作redis的客户端,它使用netty进行网络通信
2)、lettuce的bug导致netty堆外内存溢出。netty如果没有指定堆外内存,默认使用Xms的值,可以使用-Dio.netty.maxDirectMemory进行设置
解决方案:由于是lettuce的bug造成,不要直接使用-Dio.netty.maxDirectMemory去调大虚拟机堆外内存,治标不治本。
- 1)、升级lettuce客户端。但是没有解决的
- 2)、切换使用jedis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
lettuce和jedis是操作redis的底层客户端,RedisTemplate是再次封装
缓存失效
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决:缓存空对象、布隆过滤器、mvc拦截器
缓存雪崩
缓存雪崩是指在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:
- 规避雪崩:缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同缓存数据库中。
- 设置热点数据永远不过期。
- 出现雪崩:降级 熔断
- 事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存
缓存击穿
缓存雪崩和缓存击穿不同的是:
- 缓存击穿指并发查同一条数据。缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
- 缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 设置热点数据永远不过期。
- 加互斥锁:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db去数据库加载,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的
SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
缓存击穿:加锁
不好的方法是synchronized(this),肯定不能这么写 ,不具体写了
锁时序问题:之前的逻辑是查缓存没有,然后取竞争锁查数据库,这样就造成多次查数据库。
解决方法:竞争到锁后,再次确认缓存中没有,再去查数据库。

如何复制微服务:
-
idea中右键点击服务,copy configuration
-
在
program arguments: --server.port=10003
分布式缓存
本地缓存问题:每个微服务都要有缓存服务、数据更新时只更新自己的缓存,造成缓存数据不一致
解决方案:分布式缓存,微服务共用 缓存中间件
分布式锁
分布式项目时,但本地锁只能锁住当前服务,需要分布式锁
redis分布式锁的原理:setnx,同一时刻只能设置成功一个
前提,锁的key是一定的,value可以变
-
没获取到锁阻塞或者sleep一会
-
设置好了锁,玩意服务出现宕机,没有执行删除锁逻辑,这就造成了死锁
- 解决:设置过期时间
-
业务还没执行完锁就过期了,别人拿到锁,自己执行完去删了别人的锁
- 解决:锁续期(redisson有看门狗),。删锁的时候明确是自己的锁。如uuid
-
判断uuid对了,但是将要删除的时候锁过期了,别人设置了新值,那删除了别人的锁
-
解决:删除锁必须保证原子性(保证判断和删锁是原子的)。使用redis+Lua脚本(官网地址)完成CAS,脚本是原子的
-
// Lua脚本 if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end; -
//java代码中执行脚本 stringRedisTemplate.execute( new DefaultRedisScript<Long返回值类型>(script脚本, Long.class返回值类型), Arrays.asList("lock"), // 键key的集合 lockValue);
-
加锁Lua
| 参数 | 示例值 | 含义 |
|---|---|---|
| KEY个数 | 1 | KEY个数 |
| KEYS[1] | my_first_lock_name | 锁名 |
| ARGV[1] | 60000 | 持有锁的有效时间:毫秒 |
| ARGV[2] | 58c62432-bb74-4d14-8a00-9908cc8b828f:1 | 唯一标识:获取锁时set |
-- 若锁不存在:则新增锁,并设置锁重入计数为1、设置锁过期时间 -- key1 为锁 arg1为过期时间 arg2为uuid
if (redis.call('exists', KEYS[1]) == 0)
then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
-- 若锁存在,且唯一标识也匹配:则表明当前加锁请求为锁重入请求,故锁重入计数+1,并再次设置锁过期时间
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
-- 若锁存在,但唯一标识不匹配:表明锁是被其他线程占用,当前线程无权解他人的锁,直接返回锁剩余过期时间
return redis.call('pttl', KEYS[1]);
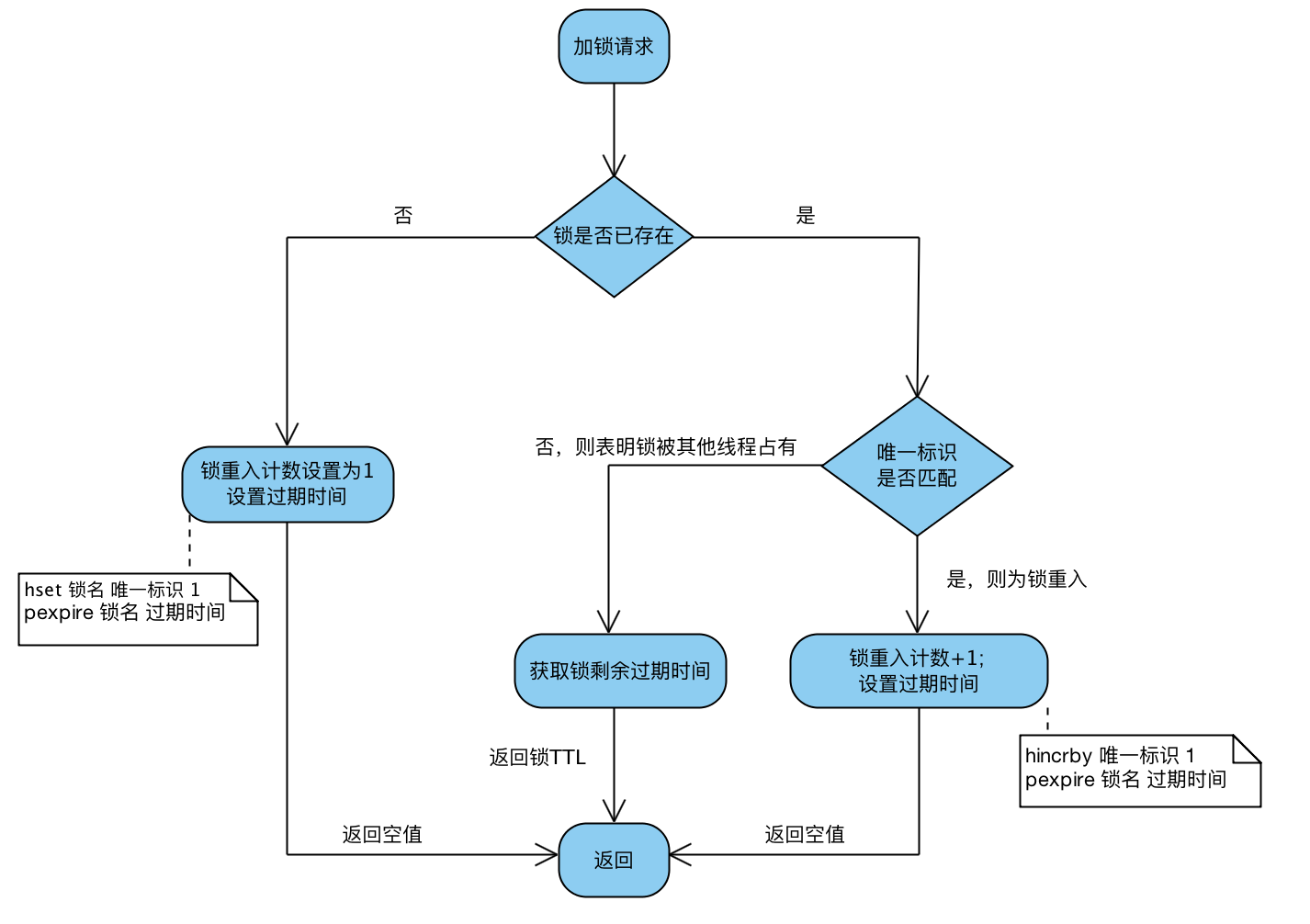
加锁流程核心就3步
Step1:尝试获取锁,这一步是通过执行加锁Lua脚本来做;
Step2:若第一步未获取到锁,则去订阅解锁消息,当获取锁到剩余过期时间后,调用信号量方法阻塞住,直到被唤醒或等待超时
Step3:一旦持有锁的线程释放了锁,就会广播解锁消息。于是,第二步中的解锁消息的监听器会释放信号量,获取锁被阻塞的那些线程就会被唤醒,并重新尝试获取锁。
解锁Lua
-- 若锁不存在:则直接广播解锁消息,并返回1
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
-- 若锁存在,但唯一标识不匹配:则表明锁被其他线程占用,当前线程不允许解锁其他线程持有的锁
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil;
end;
-- 若锁存在,且唯一标识匹配:则先将锁重入计数减1
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0) then
-- 锁重入计数减1后还大于0:表明当前线程持有的锁还有重入,不能进行锁删除操作,但可以友好地帮忙设置下过期时期
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
-- 锁重入计数已为0:间接表明锁已释放了。直接删除掉锁,并广播解锁消息,去唤醒那些争抢过锁但还处于阻塞中的线程
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
return nil;
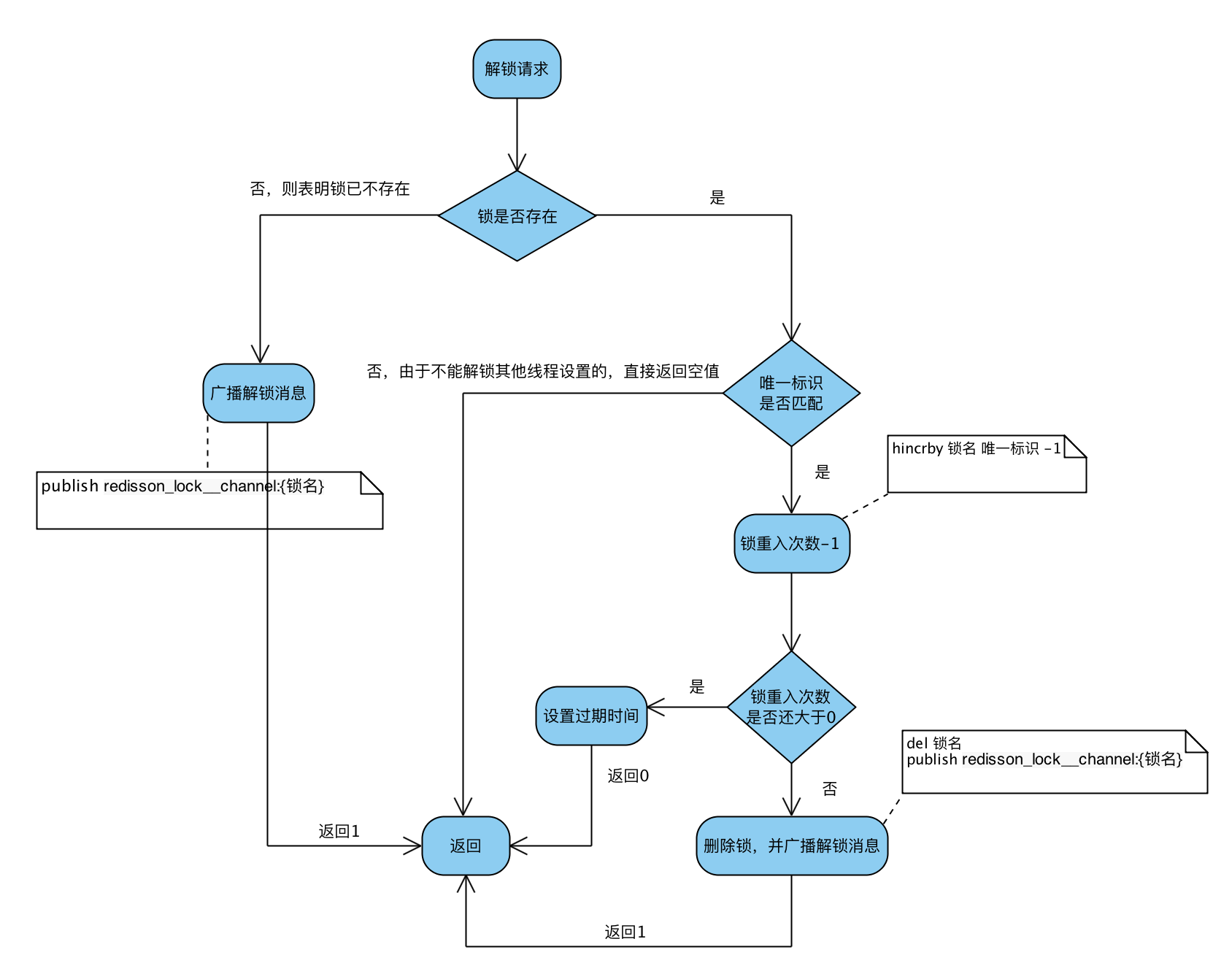
Q1:广播解锁消息有什么用?
A:是为了通知其他争抢锁阻塞住的线程,从阻塞中解除,并再次去争抢锁。
Q2:返回值0、1、nil有什么不一样?
A:当且仅当返回1,才表示当前请求真正触发了解锁Lua脚本;但客户端又并不关心解锁请求的返回值,好像没什么用?
lua脚本更多阅读:https://blog.csdn.net/asd051377305/article/details/108384490
总结:
- 加锁时判断nset
- 使用时续期
- 删除时判断uuid
最终代码:
public Map<String, List<Catalog2Vo>> getCatalogJsonDbWithRedisLock() {
// 生成uuid
String uuid = UUID.randomUUID().toString();
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
// 尝试加锁,阻塞0.5s
Boolean lock = ops.setIfAbsent("lock", uuid, 500, TimeUnit.SECONDS);
// 加锁成功
if (lock) {
// 执行业务
Map<String, List<Catalog2Vo>> categoriesDb = getCategoryMap();
// 去删除锁
String lockValue = ops.get("lock");
// get和delete原子操作
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1] then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
stringRedisTemplate.execute(
new DefaultRedisScript<Long>(script, Long.class), // 脚本和返回类型
Arrays.asList("lock"), // 参数key
lockValue); // 参数值,锁的值 uuid
// 返回db
return categoriesDb;
}else { // 加锁失败
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 睡眠0.1s后,重新调用 //自旋
return getCatalogJsonDbWithRedisLock();
}
}
上面的lua脚本写法每次用分布式锁时比较麻烦,我们可以采用redisson现有框架
分布式锁 - Redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
本文我们仅关注分布式锁的实现,更多请参考官方文档
(1) 环境搭建
导入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.17.4</version>
</dependency>
<--!这个用作连续,后面可以使用redisson-spring-boot-starter-->
开启配置: 官方文档
@Configuration
public class MyRedisConfig {
@Value("${ipAddr}")
private String ipAddr;
// redission通过redissonClient对象使用 // 如果是多个redis集群,可以配置
@Bean(destroyMethod = "shutdown")
public RedissonClient redisson() {
Config config = new Config();
// 创建单例模式的配置
config.useSingleServer().setAddress("redis://" + ipAddr + ":6379");
return Redisson.create(config);
}
}
(2) redis可重入锁
Reentrant Lock
分布式锁:官方文档
锁其实也是一种资源,各线程争抢锁操作对应到redisson中就是争抢着去创建一个hash结构,谁先创建就代表谁获得锁;hash的名称为锁名,hash里面内容仅包含一条键值对,键为redisson客户端唯一标识+持有锁线程id,值为锁重入计数;给hash设置的过期时间就是锁的过期时间。放个图直观感受下:
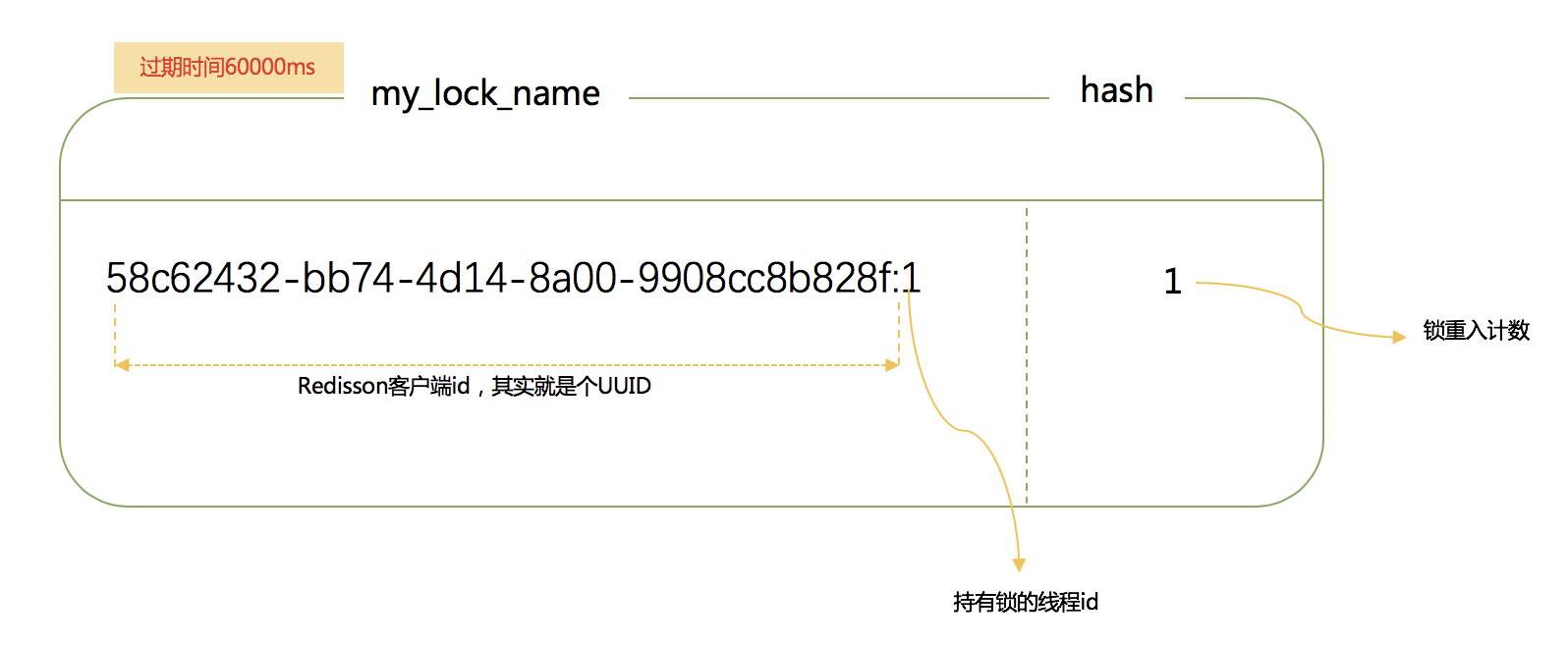
// 参数为锁名字
RLock lock = redissonClient.getLock("CatalogJson-Lock");//该锁实现了JUC.locks.lock接口
lock.lock();//阻塞等待
lock.lock();//重入锁
lock.unlock();
// 解锁放到finally // 如果这里宕机:有看门狗,不用担心
lock.unlock();
// 加锁以后10秒钟自动解锁
// 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
基于Redis的Redisson分布式可重入锁RLock Java对象实现了java.util.concurrent.locks.Lock接口。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。
锁的续期
锁的续期:大家都知道,如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟(每到20s就会自动续借成30s,是1/3的关系),也可以通过修改Config.lockWatchdogTimeout来另行指定。
lockWatchdogTimeout(监控锁的看门狗超时,单位:毫秒)
监控锁的看门狗超时时间单位为毫秒。该参数只适用于分布式锁的加锁请求中未明确使用
leaseTimeout参数的情况。如果该看门口未使用lockWatchdogTimeout去重新调整一个分布式锁的lockWatchdogTimeout超时,那么这个锁将变为失效状态。这个参数可以用来避免由Redisson客户端节点宕机或其他原因造成死锁的情况。
如果传递了锁的超时时间,就执行脚本,进行占锁;
如果没传递锁时间,代表是永久锁,使用看门狗的时间,占锁。如果返回占锁成功future,调用future.onComplete();
没异常的话调用scheduleExpirationRenewal(threadId);
重新设置过期时间,定时任务;
看门狗的原理是定时任务:重新给锁设置过期时间,新的过期时间就是看门狗的默认时间;
锁时间/3是定时任务周期;
Redisson同时还为分布式锁提供了异步执行的相关方法:
RLock lock = redisson.getLock("anyLock");
lock.lockAsync();
lock.lockAsync(10, TimeUnit.SECONDS);
Future<Boolean> res = lock.tryLockAsync(100, 10, TimeUnit.SECONDS);
RLock对象完全符合Java的Lock规范。也就是说只有拥有锁的进程才能解锁,其他进程解锁则会抛出IllegalMonitorStateException错误。但是如果遇到需要其他进程也能解锁的情况,请使用分布式信号量Semaphore 对象.
public Map<String, List<Catalog2Vo>> getCatalogJsonDbWithRedisson() {
Map<String, List<Catalog2Vo>> categoryMap=null;
RLock lock = redissonClient.getLock("CatalogJson-Lock");
lock.lock();
try {
Thread.sleep(30000);
categoryMap = getCategoryMap();
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
lock.unlock();
return categoryMap;
}
}
最佳实战:自己指定锁时间,时间长点即可
(3) 读写锁(ReadWriteLock)
基于Redis的Redisson分布式可重入读写锁RReadWriteLock Java对象实现了java.util.concurrent.locks.ReadWriteLock接口。其中读锁和写锁都继承了RLock接口。
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock");
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// 或
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// 或
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();
上锁时在redis的状态
HashWrite-Lock
key:mode value:read
key:sasdsdffsdfsdf... value:1
(4) 信号量(Semaphore)
信号量为存储在redis中的一个数字,当这个数字大于0时,即可以调用acquire()方法增加数量,也可以调用release()方法减少数量,但是当调用release()之后小于0的话方法就会阻塞,直到数字大于0
基于Redis的Redisson的分布式信号量(Semaphore)Java对象RSemaphore采用了与java.util.concurrent.Semaphore相似的接口和用法。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。
RSemaphore semaphore = redisson.getSemaphore("semaphore");
semaphore.acquire();
//或
semaphore.acquireAsync();
semaphore.acquire(23);
semaphore.tryAcquire();
//或
semaphore.tryAcquireAsync();
semaphore.tryAcquire(23, TimeUnit.SECONDS);
//或
semaphore.tryAcquireAsync(23, TimeUnit.SECONDS);
semaphore.release(10);
semaphore.release();
//或
semaphore.releaseAsync();
/**
* 车库停车
* 3车位
* 信号量也可以做分布式限流
*/
@GetMapping(value = "/park")
@ResponseBody
public String park() throws InterruptedException {
RSemaphore park = redissonClient.getSemaphore("park");
// park.acquire(); //获取一个信号、获取一个值,占一个车位,值减一,低于0会获取不成功
boolean flag = park.tryAcquire();
if (flag) {
//执行业务
System.out.println("还有空闲车位🚗");
} else {
return "error";
}
return "ok=>" + true;
}
@GetMapping(value = "/go")
@ResponseBody
public String go() {
RSemaphore park = redissonClient.getSemaphore("park");
park.release(); //释放一个车位,值加一,始终加一
return "ok";
}
(5) 闭锁(CountDownLatch)
基于Redisson的Redisson分布式闭锁(CountDownLatch)Java对象RCountDownLatch采用了与java.util.concurrent.CountDownLatch相似的接口和用法。
以下代码只有offLatch()被调用5次后 setLatch()才能继续执行
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(1);
latch.await(); // 阻塞等待减为0
// 在其他线程或其他JVM里
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();
/**
* 放假、锁门
* 1班没人了
* 5个班,全部走完,我们才可以锁大门
* 分布式闭锁
*/
@GetMapping(value = "/lockDoor")
@ResponseBody
public String lockDoor() throws InterruptedException {
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.trySetCount(5);
door.await(); //等待闭锁完成
return "放假了...";
}
@GetMapping(value = "/gogogo/{id}")
@ResponseBody
public String gogogo(@PathVariable("id") Long id) {
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.countDown(); //计数-1
return id + "班的人都走了...";
}
缓存和数据库一致性
- 双写模式:写数据库后,写缓存
- 问题:并发时,2写进入,写完DB后都写缓存。有暂时的脏数据
- 失效模式:写完数据库后,删缓存
- 问题:还没存入数据库呢,线程2又读到旧的DB了
- 解决:缓存设置过期时间,定期更新
- 解决:写数据写时,加分布式的读写锁。
解决方案:
- 如果是用户维度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可
- 如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式
- 缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
- 通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心脏数据,允许临时脏数据可忽略);
总结:
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
- 我们不应该过度设计,增加系统的复杂性
- 遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。

SpringCache
随便找篇cache文章阅读:https://blog.csdn.net/er_ving/article/details/105421572
每次都那样写缓存太麻烦了,spring从3.1开始定义了Cache、CacheManager接口来统一不同的缓存技术。并支持使用JCache(JSR-107)注解简化我们的开发
Cache接口的实现包括RedisCache、EhCacheCache、ConcurrentMapCache等
每次调用需要缓存功能的方法时,spring会检查检查指定参数的指定的目标方法是否已经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就调用方法并缓存结果后返回给用户。下次调用直接从缓存中获取。
使用Spring缓存抽象时我们需要关注以下两点:
1、确定方法需要缓存以及他们的缓存策略
2、从缓存中读取之前缓存存储的数据
(1) 配置
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
指定缓存类型并在主配置类上加上注解@EnableCaching
spring:
cache:
#指定缓存类型为redis
type: redis
redis:
# 指定redis中的过期时间为1h
time-to-live: 3600000
#如果指定了前缀就用我们指定的前缀,如果没有就默认使用缓存的名字作为前缀
# key-prefix: CACHE_
use-key-prefix: true
#是否缓存空值,防止缓存穿透
cache-null-values: true
默认使用jdk进行序列化(可读性差),默认ttl为-1永不过期,自定义序列化方式需要编写配置类
import org.springframework.boot.autoconfigure.cache.CacheProperties;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@EnableConfigurationProperties(CacheProperties.class)
@Configuration
@EnableCaching //开启springCache缓存功能
public class MyCacheConfig {
// @Autowired
// public CacheProperties cacheProperties;
@Bean
public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
//指定缓存序列化方式为json
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
//将配置文件中所有的配置都生效
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixCacheNameWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
(2) 缓存自动配置
// 缓存自动配置源码
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(CacheManager.class)
@ConditionalOnBean(CacheAspectSupport.class)
@ConditionalOnMissingBean(value = CacheManager.class, name = "cacheResolver")
@EnableConfigurationProperties(CacheProperties.class)
@AutoConfigureAfter({ CouchbaseAutoConfiguration.class, HazelcastAutoConfiguration.class,
HibernateJpaAutoConfiguration.class, RedisAutoConfiguration.class })
@Import({ CacheConfigurationImportSelector.class, // 看导入什么CacheConfiguration
CacheManagerEntityManagerFactoryDependsOnPostProcessor.class })
public class CacheAutoConfiguration {
@Bean
@ConditionalOnMissingBean
public CacheManagerCustomizers cacheManagerCustomizers(ObjectProvider<CacheManagerCustomizer<?>> customizers) {
return new CacheManagerCustomizers(customizers.orderedStream().collect(Collectors.toList()));
}
@Bean
public CacheManagerValidator cacheAutoConfigurationValidator(CacheProperties cacheProperties,
ObjectProvider<CacheManager> cacheManager) {
return new CacheManagerValidator(cacheProperties, cacheManager);
}
@ConditionalOnClass(LocalContainerEntityManagerFactoryBean.class)
@ConditionalOnBean(AbstractEntityManagerFactoryBean.class)
static class CacheManagerEntityManagerFactoryDependsOnPostProcessor
extends EntityManagerFactoryDependsOnPostProcessor {
CacheManagerEntityManagerFactoryDependsOnPostProcessor() {
super("cacheManager");
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisConnectionFactory.class)
@AutoConfigureAfter(RedisAutoConfiguration.class)
@ConditionalOnBean(RedisConnectionFactory.class)
@ConditionalOnMissingBean(CacheManager.class)
@Conditional(CacheCondition.class)
class RedisCacheConfiguration {
@Bean // 放入缓存管理器
RedisCacheManager cacheManager(CacheProperties cacheProperties,
CacheManagerCustomizers cacheManagerCustomizers,
ObjectProvider<org.springframework.data.redis.cache.RedisCacheConfiguration> redisCacheConfiguration,
ObjectProvider<RedisCacheManagerBuilderCustomizer> redisCacheManagerBuilderCustomizers,
RedisConnectionFactory redisConnectionFactory, ResourceLoader resourceLoader) {
RedisCacheManagerBuilder builder = RedisCacheManager.builder(redisConnectionFactory).cacheDefaults(
determineConfiguration(cacheProperties, redisCacheConfiguration, resourceLoader.getClassLoader()));
List<String> cacheNames = cacheProperties.getCacheNames();
if (!cacheNames.isEmpty()) {
builder.initialCacheNames(new LinkedHashSet<>(cacheNames));
}
redisCacheManagerBuilderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(builder));
return cacheManagerCustomizers.customize(builder.build());
}
(3) 缓存使用
- @Cacheable存放缓存
- @CacheEvict清空缓存
// 调用该方法时会将结果缓存,缓存名为category,key为方法名
@Cacheable(value = {"category"}, // value等同于cacheNames
key = "#root.methodName",// key如果是字符串"''"
sync = true) // sync表示该方法的缓存被读取时会加锁(本地锁🔒)
public Map<String, List<Catalog2Vo>> getCatalogJsonDbWithSpringCache() {
return getCategoriesDb();
}
//调用该方法会删除缓存category下的所有cache,如果要删除某个具体,用key="''"
// 如果要清空多个缓存,用@Caching(evict={@CacheEvict(value="")})
// @Caching(evict = {
// @CacheEvict(value = {"catelog"},key="'getLevel1'"),
// @CacheEvict(value = {"catelog"},key = "'getCatelogJson'")
// })
@Override
@CacheEvict(value = {"category"},allEntries = true)
public void updateCascade(CategoryEntity category) {
this.updateById(category);
if (!StringUtils.isEmpty(category.getName())) {
categoryBrandRelationService.updateCategory(category);
}
}
(4) SpringCache原理与不足
读模式
- 缓存穿透:查询一个null数据。
- 解决方案:缓存空数据,可通过
spring.cache.redis.cache-null-values=true
- 解决方案:缓存空数据,可通过
- 缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方案:加锁 ? 默认是无加锁的;
- 使用
sync = true来解决击穿问题*(加的是本地锁)*
- 使用
- 缓存雪崩:大量的key同时过期。解决:加随机时间。
写模式:(缓存与数据库一致)
- 读写加锁。
- 引入Canal,感知到MySQL的更新去更新Redis
- 读多写多,直接去数据库查询就行
总结:
常规数据(读多写少,即时性,一致性要求不高的数据,完全可以使用Spring-Cache):
写模式(只要缓存的数据有过期时间就足够了)
特殊数据:特殊设计
评论